Оптимизируйте настройки виртуальной памяти и кэша. Как оптимизировать работу оперативной памяти
Одна из самых раздражающих вещей в Windows - это то, что она может зависнуть на несколько секунд, судорожно делая что-то на диске. Одна из причин - работа Windows с дисковой виртуальной памятью, заложенная по умолчанию. Windows загружает драйверы и приложения в память, пока она не заполнится, а затем начинает использовать часть жесткого диска, чтобы «подкачать» информацию, освобождая оперативную память для задач более высокого приоритета. Файл, который использует Windows для этого типа «виртуальной памяти» файл подкачки pagefile.sys, - хранится в корневом каталоге диска.
Поскольку жесткий диск работает медленнее, чем физическая оперативная память, то чем больше Windows подкачивает, тем медленнее работает компьютер. Вот почему добавление оперативной памяти ускоряет работу - уменьшается необходимость в виртуальной памяти. Независимо от объема установленной физической памяти есть способ улучшить производительность виртуальной памяти. Настройки Windows по умолчанию довольно консервативны, но, к счастью, их можно изменить для улучшения производительности. Важно помнить, что эксперименты с такими настройками оправданны только для систем с объемными жесткими дисками, когда виртуальной памяти можно уделить больше дискового пространства.
Часть 1: Настройки виртуальной памяти
Одна из причин того, что настройки по умолчанию приводят к низкой производительности, - файл подкачки растет и уменьшается при использовании, быстро становясь фрагментированным. Первый шаг должен устранить эту проблему, установив фиксированный размер файла подкачки.
Заметьте, что создание фиксированного файла подкачки обеспечит более постоянный объем свободного дискового пространства. Если жесткий диск переполняется, запретите Windows использовать последний бит свободного пространства.
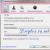
1. В Панели управления откройте страницу Система и нажмите ссылку Дополнительные параметры системы.
2. Под вкладкой Дополнительно в разделе Быстродействие нажмите кнопку Параметры.
3. На странице параметров быстродействия выберите вкладку Дополнительно и затем нажмите Изменить, чтобы открыть окно виртуальной памяти.
4. Выключите параметр Автоматически выбирать объем файла подкачки, чтобы получить доступ к настройкам в этом окне.
5. Настройки виртуальной памяти устанавливаются отдельно для каждого диска. Если у вас только один диск, виртуальная память уже включена для этого диска. Если вы используете больше одного диска или раздела, то виртуальная память по умолчанию будет включена только на диске с Windows. Начните с диска, который в настоящий момент содержит файл подкачки.
Другой способ запретить Windows интенсивно использовать жесткий диск - отключение виртуальной памяти. Еще лучше будет переместить файл подкачки на другой физический диск, в этом случае при работе Windows с виртуальной памятью процесс не будет высасывать все соки из основного диска компьютера,
6. Чтобы установить фиксированный размер виртуальной памяти, отметьте Указать размер, а затем введите одно и то же значение в Исходный размер и в Максимальный размер.
Объем определите сами. Если на диске есть место, то выделите место в 2-3 раза больше объема установленной оперативной памяти. Можно поэкспериментировать с различными размерами для того, чтобы определить наиболее подходящий.
7. Важно: после того как вы сделали изменения, нажмите Задать или ОК для фиксации изменений перед переходом к другому диску.
8. Нажмите ОК в каждом из трех открытых диалоговых окон.
Если вы просто изменили размеры файла подкачки, изменение сразу вступит в силу. Но если вы добавили файл подкачки на каком-либо диске, то необходимо перезапустить Windows, прежде чем вы сможете использовать новые настройки.
Часть 2: Дефрагментируйте файл подкачки
Шаги, описанные в предыдущем разделе, устраняют возможность фрагментации файла подкачки, но они не исправят его, если он уже фрагментирован. Для лучшей производительности виртуальная память должна быть дефрагментирована, но если файл подкачки имеет фиксированный размер, то это нужно сделать только один раз. Есть несколько способов дефрагментировать файл подкачки:
Используйте PerfectDisk
Используйте усовершенствованный дефрагментатор PerfectDisk. Дайте ему команду дефрагментировать системные файлы, и он запланирует дефрагментацию при следующем запуске Windows.
Увеличение производительности кэш-памяти
Формула для среднего времени доступа к памяти в системах с кэш-памятью выглядит следующим образом:
Среднее время доступа = Время обращения при попадании + Доля промахов x Потери при промахе
Эта формула наглядно показывает пути оптимизации работы кэш-памяти: сокращение доли промахов, сокращение потерь при промахе, а также сокращение времени обращения к кэш-памяти при попадании. На рисунке 5.38 кратко представлены различные методы, которые используются в настоящее время для увеличения производительности кэш-памяти. Использование тех или иных методов определяется прежде всего целью разработки, при этом конструкторы современных компьютеров заботятся о том, чтобы система оказалась сбалансированной по всем параметрам.
Зачем увеличивать кэш?
Первичная причина увеличения объема встроенного кэша может заключаться в том, что кэш-память в современных процессорах работает на той же скорости, что и сам процессор. Частота процессора в этом случае никак не меньше 3200 MГц. Больший объем кэша позволяет процессору держать большие части кода готовыми к выполнению. Такая архитектура процессоров сфокусирована на уменьшении задержек, связанных с простоем процессора в ожидании данных. Современные программы, в том числе игровые, используют большие части кода, который необходимо извлекать из системной памяти по первому требованию процессора. Уменьшение промежутков времени, уходящих на передачу данных от памяти к процессору, - это надежный метод увеличения производительности приложений, требующих интенсивного взаимодействия с памятью. Кэш L3 имеет немного более высокое время ожидания, чем L 1 и 2, это вполне естественно. Хоть он и медленнее, но все-таки он значительно более быстрый, чем обычная память. Не все приложения выигрывают от увеличения объема или скорости кэш-памяти. Это сильно зависит от природы приложения.
Если большой объем встроенного кэша - это хорошо, тогда что же удерживало Intel и AMD от этой стратегии ранее? Простым ответом является высокая себестоимость такого решения. Резервирование пространства для кэша очень дорого. Стандартный 3.2GHz Northwood содержит 55 миллионов транзисторов. Добавляя 2048 КБ кэша L3, Intel идет на увеличение количества транзисторов до 167 миллионов. Простой математический расчет покажет нам, что EE - один из самых дорогих процессоров.
Сайт AnandTech провел сравнительное тестирование двух систем, каждая из которых содержала два процессора - Intel Xeon 3,6 ГГц в одном случае и AMD Opteron 250 (2,4 ГГц) - в другом. Тестирование проводилось для приложений ColdFusion MX 6.1, PHP 4.3.9, и Microsoft .NET 1.1. Конфигурации выглядели следующим образом:
Dual Opteron 250;
2 ГБ DDR PC3200 (Kingston KRX3200AK2);
Системная плата Tyan K8W;
Dual Xeon 3.6 ГГц;
Материнская плата Intel SE7520AF2;
ОС Windows 2003 Server Web Edition (32 бит);
1 жесткий IDE 40 ГБ 7200 rpm, кэш 8 МБ
На приложениях ColdFusion и PHP, не оптимизированных под ту или иную архитектуру, чуть быстрее (2,5-3%) оказались Opteron"ы, зато тест с.NET продемонстрировал последовательную приверженность Microsoft платформе Intel, что позволило паре Xeon"ов вырваться вперед на 8%. Вывод вполне очевиден: используя ПО Microsoft для веб-приложений, есть смысл выбрать процессоры Intel, в других случаях несколько лучшим выбором будет AMD.
Больше - не всегда лучше
Частота промахов при обращении к кэш-памяти может быть значительно снижена за счет увеличения емкости кэша. Но большая кэш-память требует больше энергии, генерирует больше тепла и увеличивает число бракованных микросхем при производстве.
Один из способов обойти эти трудности -- передача логики управления кэш-памятью от аппаратного обеспечения к программному.
«Компилятор потенциально в состоянии анализировать поведение программы и генерировать команды по переносу данных между уровнями памяти», -- отметил Шен.
Управляемая программным образом кэш-память сейчас существует лишь в исследовательских лабораториях. Возможные трудности связаны с тем, что придется переписывать компиляторы и перекомпилировать унаследованный код для всех процессоров нового поколения.
Большинство программистов представляют вычислительную систему как процессор, который выполняет инструкции, и память, которая хранит инструкции и данные для процессора. В этой простой модели память представляется линейным массивом байтов и процессор может обратиться к любому месту в памяти за константное время. Хотя это эффективная модель для большинства ситуаций, она не отражает того, как в действительности работают современные системы.
В действительности система памяти образует иерархию устройств хранения с разными ёмкостями, стоимостью и временем доступа. Регистры процессора хранят наиболее часто используемые данные. Маленькие быстрые кэш-памяти, расположенные близко к процессору, служат буферными зонами, которые хранят маленькую часть дынных, расположеных в относительно медленной оперативной памяти. Оперативная память служит буфером для медленных локальных дисков. А локальные диски служат буфером для данных с удалённых машин, связанных сетью.
Иерархия памяти работает, потому что хорошо написанные программы имеют тенденцию обращаться к хранилищу на каком-то конкретном уровне более часто, чем к хранилищу на более низком уровне. Так что хранилище на более низком уровне может быть медленнее, больше и дешевле. В итоге мы получаем большой объём памяти, который имеет стоимость хранилища в самом низу иерархии, но доставляет данные программе со скоростью быстрого хранилища в самом верху иерархии.
Как программист, вы должны понимать иерархию памяти, потому что она сильно влияет на производительность ваших программ. Если вы понимаете как система перемещает данные вверх и вниз по иерархии, вы можете писать такие программы, которые размещают свои данные выше в иерархии, так что процессор может получить к ним доступ быстрее.
В этой статье мы исследуем как устройства хранения организованы в иерархию. Мы особенно сконцентрируемся на кэш-памяти, которая служит буферной зоной между процессором и оперативно памятью. Она оказывает наибольшее влияние на производительность программ. Мы введём важное понятие локальности , научимся анализировать программы на локальность, а также изучим техники, которые помогут увеличить локальность ваших программ.
На написание этой статьи меня вдохновила шестая глава из книги Computer Systems: A Programmer"s Perspective . В другой статье из этой серии, «Оптимизация кода: процессор» , мы также боремся за такты процессора.
Память тоже имеет значение
Рассмотрим две функции, которые суммируют элементы матрицы. Они практически одинаковы, только первая функция обходит элементы матрицы построчно, а вторая - по столбцам.
Int matrixsum1(int size, int M) { int sum = 0; for (int i = 0; i < size; i++) { for (int j = 0; j < size; j++) { sum += M[i][j]; // обходим построчно } } return sum; } int matrixsum2(int size, int M) { int sum = 0; for (int i = 0; i < size; i++) { for (int j = 0; j < size; j++) { sum += M[j][i]; // обходим по столбцам } } return sum; }
Обе функции выполняют одно и то же количество инструкций процессора. Но на машине с Core i7 Haswell первая функция выполняется в 25 раз быстрее для больших матриц. Этот пример хорошо демонстрирует, что память тоже имеет значение . Если вы будете оценивать эффективность программ только в терминах количества выполняемых инструкций, вы можете писать очень медленные программы.
Данные имеют важное свойство, которое мы называем локальностью . Когды мы работаем над данными, желательно чтобы они находились в памяти рядом. Обход матрицы по столбцам имеет плохую локальность, потому что матрица хранится в памяти построчно. О локальности мы поговорим ниже.
Иерархия памяти
Современная система памяти образует иерархию от быстрых типов памяти маленького размера до медленных типов памяти большого размера. Мы говорим, что конкретный уровень иерархии кэширует или является кэшем для данных, расположенных на более низком уровне. Это значит, что он содержит копии данных с более низкого уровня. Когда процессор хочет получить какие-то данные, он их сперва ищет на самых быстрых высоких уровнях. И спускается на более низкие, если не может найти.
На вершине иерархии находятся регистры процессора. Доступ к ним занимает 0 тактов, но их всего несколько штук. Далее идёт несколько килобайт кэш-памяти первого уровня, доступ к которой занимает примерно 4 такта. Потом идёт пара сотен килобайт более медленной кэш-памяти второго уровня. Потом несколько мегабайт кэш-памяти третьего уровня. Она гораздо медленней, но всё равно быстрее оперативной памяти. Далее расположена относительно медленная оперативная память.
Оперативную память можно рассматривать как кэш для локального диска. Диски это рабочие лошадки среди устройств хранения. Они большие, медленные и стоят дёшево. Компьютер загружает файлы с диска в оперативную память, когда собирается над ними работать. Разрыв во времени доступа между оперативной памятью и диском колоссальный. Диск медленнее оперативной памяти в десятки тысяч раз, и медленнее кэша первого уровня в миллионы раз. Выгоднее обратиться несколько тысяч раз к оперативной памяти, чем один раз к диску. На это знание опираются такие структуры данных, как B-деревья , которые стараются разместить больше информации в оперативной памяти, пытаясь избежать обращения к диску любой ценой.
Локальный диск сам может рассматриваться как кэш для данных, расположенных на удалённых серверах. Когда вы посещаете веб-сайт, ваш браузер сохраняет изображения с веб-страницы на диске, чтобы при повторном посещении их не нужно было качать. Существуют и более низкие иерархии памяти. Крупные датацентры, типа Google, сохраняют большие объёмы данных на ленточных носителях, которые хранятся где-то на складах, и когда понадобятся, должны быть присоеденены вручную или роботом.
Современная система имеет примерно такие характеристики:
Быстрая память стоит очень дорого, а медленная очень дёшево. Это великая идея архитекторов систем совместить большие размеры медленной и дешёвой памяти с маленькими размерами быстрой и дорогой. Таким образом система может работать на скорости быстрой памяти и иметь стоимость медленной. Давайте разберёмся как это удаётся.
Допустим, ваш компьютер имеет 8 ГБ оперативной памяти и диск размером 1000 ГБ. Но подумайте, что вы не работаете со всеми данными на диске в один момент. Вы загружаете операционную систему, открываете веб-браузер, текстовый редактор, пару-тройку других приложений и работаете с ними несколько часов. Все эти приложения помещаются в оперативной памяти, поэтому вашей системе не нужно обращаться к диску. Потом, конечно, вы закрываете одно приложение и открываете другое, которое приходится загрузить с диска в оперативную память. Но это занимает пару секунд, после чего вы несколько часов работаете с этим приложением, не обращаясь к диску. Вы не особо замечаете медленный диск, потому что в один момент вы работаете только с небольшим бъёмом данных, которые кэшируются в оперативной памяти. Вам нет смысла тратить огромные деньги на установку 1024 ГБ оперативной памяти, в которую можно было бы загрузить содержимое всего диска. Если бы вы это сделали, вы бы почти не заметили никакой разницы в работе, это было бы «деньги на ветер».
Так же дело обстоит и с маленькими кэшами процессора. Допустим вам нужно выполнить вычисления над массивом, который содержит 1000 элементов типа int . Такой массив занимает 4 КБ и полностью помещается в кэше первого уровня размером 32 КБ. Система понимает, что вы начали работу с определённым куском оперативной памяти. Она копирует этот кусок в кэш, и процессор быстро выполняет действия над этим массивом, наслаждаясь скоростью кэша. Потом изменённый массив из кэша копируется назад в оперативную память. Увеличение скорости оперативной памяти до скорости кэша не дало бы ощутимого прироста в производительности, но увеличило бы стоимость системы в сотни и тысячи раз. Но всё это верно только если программы имеют хорошую локальность.
Локальность
Локальность - основная концепция этой статьи. Как правило, программы с хорошей локальностью выполняются быстрее, чем программы с плохой локальностью. Локальность бывает двух типов. Когда мы обращаемся к одному и тому же месту в памяти много раз, это временнáя локальность . Когда мы обращаемся к данным, а потом обращаемся к другим данным, которые расположены в памяти рядом с первоначальными, это пространственная локальность .
Рассмотрим, программу, которая суммирует элементы массива:
Int sum(int size, int A) { int i, sum = 0; for (i = 0; i < size; i++) sum += A[i]; return sum; }
В этой программе обращение к переменным sum и i происходит на каждой итерации цикла. Они имеют хорошую временную локальность и будут расположены в быстрых регистрах процессора. Элементы массива A имеют плохую временную локальность, потому что к каждому элементу мы обращаемся только по разу. Но зато они имеют хорошую пространственную локальность - тронув один элемент, мы затем трогаем элементы рядом с ним. Все данные в этой программе имеют или хорошую временную локальность или хорошую пространственную локальность, поэтому мы говорим что программа в общем имеет хорошую локальность.
Когда процессор читает данные из памяти, он их копирует в свой кэш, удаляя при этом из кэша другие данные. Какие данные он выбирает для удаления тема сложная. Но результат в том, что если к каким-то данным обращаться часто, они имеют больше шансов оставаться в кэше. В этом выгода от временной локальности. Программе лучше работать с меньшим количеством переменных и обращаться к ним чаще.
Перемещение данных между уровнями иерархии осуществляется блоками определённого размера. К примеру, процессор Core i7 Haswell перемещает данные между своими кэшами блоками размером в 64 байта. Рассмотрим конкретный пример. Мы выполняем программу на машине с вышеупомянутым процессором. У нас есть массив v , содержащий 8-байтовые элементы типа long . И мы последовательно обходим элементы этого массива в цикле. Когда мы читаем v , его нет в кэше, процессор считывает его из оперативной памяти в кэш блоком размером 64 байта. То есть в кэш отправляются элементы v –v . Далее мы обходим элементы v , v , ..., v . Все они будут в кэше и доступ к ним мы получим быстро. Потом мы читаем элемент v , которого в кэше нет. Процессор копирует элементы v –v в кэш. Мы быстро обходим эти элементы, но не находим в кэше элемента v . И так далее.
Поэтому если вы читаете какие-то байты из памяти, а потом читаете байты рядом с ними, они наверняка будут в кэше. В этом выгода от пространственной локальности. Нужно стремиться на каждом этапе вычисления работать с данными, которые расположены в памяти рядом.
Желательно обходить массив последовательно, читая его элементы один за другим. Если нужно обойти элементы матрицы, то лучше обходить матрицу построчно, а не по столбцам. Это даёт хорошую пространственную локальность. Теперь вы можете понять, почему функция matrixsum1 работала медленнее функции matrixsum2 . Двумерный массив расположен в памяти построчно: сначала расположена первая строка, сразу за ней идёт вторая и так далее. Первая функция читала элементы матрицы построчно и двигалась по памяти последовательно, будто обходила один большой одномерный массив. Эта функция в основном читала данные из кэша. Вторая функция переходила от строки к строке, читая по одному элементу. Она как бы прыгала по памяти слева-направо, потом возвращалась в начало и опять начинала прыгать слева-направо. В конце каждой итерации она забивала кэш последними строками, так что в начале следующей итерации первых строк кэше не находила. Эта функция в основном читала данные из оперативной памяти.
Дружелюбный к кэшу код
Как программисты вы должны стараться писать код, который, как говорят, дружелюбный к кэшу (cache-friendly ). Как правило, основной объём вычислений производится лишь в нескольких местах программы. Обычно это несколько ключевых функций и циклов. Если есть вложенные циклы, то внимание нужно сосредоточить на самом внутреннем из циклов, потому что код там выполняется чаще всего. Эти места программы и нужно оптимизировать, стараясь улучшить их локальность.
Вычисления над матрицами очень важны в приложениях анализа сигналов и научных вычислениях. Если перед программистами встанет задача написать функцию перемножения матриц, то 99.9% из них напишут её примерно так:
Void matrixmult1(int size, double A, double B, double C) { double sum; for (int i = 0; i < size; i++) for (int j = 0; j < size; j++) { sum = 0.0; for (int k = 0; k < size; k++) sum += A[i][k]*B[k][j]; C[i][j] = sum; } }
Этом код дословно повторяет математическое определение перемножения матриц. Мы обходим все элементы окончательной матрицы построчно, вычисляя каждый из них один за другим. В коде есть одна неэффективность, это выражение B[k][j] в самом внутреннем цикле. Мы обходим матрицу B по стобцам. Казалось бы, ничего с этим не поделаешь и придётся смириться. Но выход есть. Можно переписать то же вычисление по другому:
Void matrixmult2(int size, double A, double B, double C) { double r; for (int i = 0; i < size; i++) for (int k = 0; k < size; k++) { r = A[i][k]; for (int j = 0; j < size; j++) C[i][j] += r*B[k][j]; } }
Теперь функция выглядит очень странно. Но она делает абсолютно то же самое. Только мы не вычисляем каждый элемент окончательной матрицы за раз, мы как бы вычисляем элементы частично на каждой итерации. Но ключевое свойство этого кода в том, что во внутреннем цикле мы обходим обе матрицы построчно. На машине с Core i7 Haswell вторая функция работает в 12 раз быстрее для больших матриц. Нужно быть действительно мудрым программистом, чтобы организовать код таким образом.
Блокинг
Существует техника, которая называется блокинг . Допустим вам надо выполнить вычисление над большим объёмом данных, которые все не помещаются в кэше высокого уровня. Вы разбиваете эти данные на блоки меньшего размера, каждый из которых помещается в кэше. Выполняете вычисления над этими блоками по отдельности и потом объёдиняете результат.
Можно продемонстрировать это на примере. Допустим у вас есть ориентированный граф, представленный в виде матрицы смежности. Это такая квадратная матрица из нулей и единиц, так что если элемент матрицы с индексом (i, j) равен единице, то существует грань от вершины графа i к вершине j. Вы хотите превратить этот ориентированный граф в неориентированный. То есть, если есть грань (i, j), то должна появиться противоположная грань (j, i). Обратите внимание, что если представить матрицу визуально, то элементы (i, j) и (j, i) являются симметричными относительно диагонали. Эту трансформацию нетрудно осуществить в коде:
Void convert1(int size, int G) { for (int i = 0; i < size; i++) for (int j = 0; j < size; j++) G[i][j] = G[i][j] | G[j][i]; }
Блокинг появляется естественным образом. Представьте перед собой большую квадратную матрицу. Теперь иссеките эту матрицу горизонтальными и вертикальными линиями, чтобы разбить её, скажем, на 16 равных блока (четыре строки и четыре столбца). Выберите два любых симметричных блока. Обратите внимание, что все элементы в одном блоке имеют симметричные элементы в другом блоке. Это наводит на мысль, что ту же операцию можно совершать над каждым блоком поочерёдно. В этом случае на каждом этапе мы будем работать только с двумя блоками. Если блоки сделать достаточно маленького размера, то они поместятся в кэше высокого уровня. Выразим эту идею в коде:
Void convert2(int size, int G) { int block_size = size / 12; // разбить на 12*12 блоков // представим, что делится без остатка for (int ii = 0; ii < size; ii += block_size) { for (int jj = 0; jj < size; jj += block_size) { int i_start = ii; // индекс i для блока принимает значения [j] = G[i][j] | G[j][i]; } } }
Нужно заметить, что блокинг не улучшит производительность на системах с мощными процессорами, которые хорошо делают предвыборку. На системах, которые не делают предвыборки, блокинг может сильно увеличить производительность.
На машине с процессором Core i7 Haswell вторая функция не выполняется быстрее. На машине с более простым процессором Pentium 2117U вторая функция выполняется в 2 раза быстрее . На машинах, которые не выполняют предвыборку, производительность улучшилась бы ещё сильнее.
Какие алгоритмы быстрее
Все знают из курсов по алгоритмам, что нужно выбирать хорошие алгоритмы с наименьшей сложностью и избегать плохих алгоритмов с высокой сложностью. Но эти сложности оценивают выполнение алгоритма на теоретической машине, созданной нашей мыслью. На реальных машинах теоретически плохой алгоритм может выполнятся быстрее теоретически хорошего. Вспомните, что получить данные из оперативной памяти занимает 200 тактов, а из кэша первого уровня 4 такта - это в 50 раз быстрее. Если хороший алгоритм часто трогает память, а плохой алгоритм размещает свои данные в кэше, хороший может выполняться медленнее плохого. Также хороший алгоритм может хуже выполняться на процессоре, чем плохой. К примеру, хороший алгоритм вносит зависимость данных и не может загрузить конвеер, а плохой лишён этой проблемы и на каждом такте отправляет в конвеер новую инструкцию. Иными словами, сложность алгоритма это ещё не всё. То, как алгоритм будем выполняться на конкретной машине с конкретными данными, имеет значение.
Представим, что вам нужно реализовать очередь целых чисел, и новые элементы могут добавляться в любую позицию очереди. Вы выбираете между двумя реализациями: массив и связный список. Чтобы добавить элемент в середину массива, нужно сдвинуть вправо половину массива, что занимает линейное время. Чтобы добавить элемент в середину списка, нужно дойти по списку до середины, что также занимает линейное время. Вы думаете, что раз сложности у них одинаковые, то лучше выбрать список. Тем более у списка есть одно хорошее свойство. Список может расти без ограничения, а массив придётся расширять, когда он заполнится. Давайте представим что длина очереди 1000 элементов и нам нужно вставить элемент в середину очереди. Элементы списка хаотично разбросаны по памяти, а получить данные из памяти занимает 200 тактов. Поэтому чтобы обойти 500 элементов, нам понадобится 500*200=100"000 тактов. Массив расположен в памяти последовательно, что позволит нам наслаждаться скоростью кэша первого уровня с временем доступа 4 такта. Используя несколько оптимизаций, мы можем двигать элементы, тратя 1-4 такта на элемент. Мы сдвинем половину массива максимум за 500*4=2000 тактов. Это быстрее в 50 раз .
Если в предыдущем примере все добавления были бы в начало очереди, реализация со связным списком была бы более эффективной. Если какая-то доля добавлений была бы куда-то в середину очереди, реализация в виде массива могла бы стать лучшим выбором. Мы бы тратили такты на одних операциях и экономили такты на других операциях. И в итоге могли бы остаться в выигрыше. Нужно учитывать все аспекты каждой конкретной ситуации.
Заключение
Система памяти организована в виде иерархии устройств хранения с маленькими и быстрыми устройствами вверху иерархии и большими и медленными устройствами внизу. Программы с хорошей локальностью работают с данными из кэшей процессора. Программы с плохой локальностью работают с данными из относительно медленной оперативной памяти.
Программисты, которые понимают природу иерархии памяти, могут структурируют свои программы так, чтобы данные располагались как можно выше в иерархии и процессор получал их быстрее.
- Сконцентрируйте ваше внимание на внутренних циклах. Именно там происходит наибольший объём вычислений и обращений к памяти.
- Постарайтесь максимизировать пространственную локальность, читая объекты из памяти последовательно, в том порядке, в котором они в ней расположены.
- Постарайтесь максимизировать временную локальность, используя объекты данных как можно чаще после того, как они были прочитаны из памяти.
На многих сайтах компьютерной тематики обязательно найдутся ссылки на программы, которые обещают в один клик улучшить работу нашего компьютера и превратить старенький медленный компьютер в скоростной «космолет». о том, что подобные «однокликовые» оптимизаторы как минимум бесполезны, и что к вопросу оптимизации необходимо подходить совершенно иначе — более продуманно и уж никак не с инструментом вида «в один клик». Также встречаются и оптимизаторы оперативной памяти, которые в линейке бесполезных утилит стоят особо высоко, потому что они не только не приносят никакой пользы, но и снижают скорость работы вашего компьютера. И сейчас я объясню почему.
На чем основана популярность оптимизаторов памяти?
Популярность оптимизаторов памяти основывается на нашем убеждении, что малый объем свободной памяти — это очень плохо. Хотя на самом деле никакой трагедии в этом нет, потому что это хорошо! Это может показаться странным, но это так.
Что такое «свободная память»?
Действительно, свободной памяти всегда мало… Однако понятия немного изменились за последние пять-семь лет. Теперь свободная память большого объема означает не большую эффективность работы системы, а наоборот меньшую. Дело в том, что современные операционные системы оставляют свободным лишь тот объем памяти, который может экстренно потребоваться какому-то вновь стартовавшему приложению или работающей программе в процессе ее деятельности. Всю остальную зарезервированную память система расходует на запущенные программы и службы.
Что такое кэш?
Кэш — это данные, которые использовались системой или программами, и которые были зарезервированы в оперативной памяти на тот случай, если они еще понадобятся. Данные резервируются именно в памяти потому, что скорость чтения из оперативной памяти в разы выше, чем скорость чтения с жесткого диска. В случае необходимости система снова использует эти данные и без задержек выведет результат пользователю на экране. Если бы эти данные каждый раз резервировались на жестком диске, то скорость их загрузки была бы значительно ниже, что сильно бы замедляло скорость работы системы в целом и создавало повышенную нагрузку на жестких диск.
В качестве аналогии можно привести пример с кэшем браузера, который хранится на жестком диске компьютера (графика, стили, скрипты, флэш-анимация и прочее). Загружать все эти данные из интернета для каждой отделной страницы было бы слишком расточительно и занимало бы слишком много времени. Потому все современные браузеры резервируют эти «тяжелые» данные на жестком диске и подгружают только основной контент, что в разы ускоряет отображение страниц для пользователя. Подобный принцип используется и при работе системного кэша, который хранится в оперативной памяти для быстрого доступа к данным.
Поэтому стоит менять свои взгляды на память: в новых операционных системах понятие «свободная память» есть синоним бездарно пропадающих без дела ресурсов. Это всего лишь резерв, чтобы система могла выдать его очередному приложению на некоторое время, пока освобождается занятая память. Windows сама освободит нужный приложению объем оперативной памяти от данных кэша или перебросит данные редко используемых программ в файл подкачки.
Заметьте, делает все это операционная система самостоятельно, без помощи каких-либо оптимизаторов. Тогда зачем нужны такие «очистители памяти» и «бустеры»?
Как работают утилиты по освобождению памяти?
Основных принципов их работы всего два:
- Они используют функцию EmptyWorkingSet из API Windows. Эта функция делает принудительный сброс неиспользуемых данных из памяти в файл подкачки на жестком диске компьютера. Визуально в диспетчере задач количество свободной памяти увеличится, но станут ли быстрее работать программы? Однозначно — нет. Потому что скорость чтения с диска значительно ниже, чем скорость чтения из оперативной памяти компьютера.
- Второй метод «очистки памяти» — приложение-оптимизатор требует у системы под себя достаточно много памяти. Система сама принудительно освобождает память от кэша и неиспользуемых данных. Но минут через десять Windows поймет, что программе-оптимизатору эта память не требуется и отдаст ее обратно под кэш и данные других программ.
Что делать, чтобы реально помочь своей системе с оптимизацией памяти?
Ответ банален — просто не мешайте работать Windows и следуйте простым советам.
- Старайтесь не запускать слишком много приложений без дела. Есть пользователи, которые после редактирования текста не закрывают окно Word. А документов за день они редактируют много и все они висят в фоне и «съедают» память.
- Удалите ненужные приложения с компьютера, особенно если они «висят» в автозагрузке.
- Добавьте память физически, если ваш компьютер это позволяет. Стоимость оперативной памяти сейчас весьма демократична, а эффект от увеличения памяти вы увидите сразу!
Все сторонние «оптимизаторы» и «бустеры» памяти как минимум бесполезны, а как максимум замедлят работу системы, показав кратковременное освобождение небольшого количества оперативной памяти.
Делиться с ближним своим для нас, божьих тварей, это очень характерно, считается добродетелью, и вообще, как утверждает , положительно отражается на карме. Однако в мире , созданном архитекторами микропроцессоров, такое поведение не всегда приводит к хорошим результатам, особенно если это касается разделения памяти между потоками.
Мы все «немного читали» об оптимизации работы с памятью, и у нас отложилось, что полезно, когда «кэш остается горячим», то есть данные, к которым часто обращаются потоки, должны быть компактными и находиться в ближайшем к процессорному ядру кэше. Все так, но когда дело доходит до того, чтобы делиться доступом, потоки становятся злейшими врагами [производительности], а кэш не просто горячий, он аж «горит адским огнем » – такая во круг него разворачивается борьба.
Ниже мы рассмотрим простой, но показательный случай возникновения проблем производительности многопоточных программ, а потом я дам несколько общих рекомендаций, как избежать проблемы потери эффективности вычислений из-за разделения кэша между потоками.
Рассмотрим случай, который хорошо описан в Intel64 and IA-32 Architectures Optimization Manual , однако про который программисты часто забывают, работая со массивами структур в могопоточном режиме. Они допускают обращение (с модификацией) потоков к данным структур, расположенных очень близко друг к другу, а именно в блоке, равном длине одной кэш-линии (64 байт). Мы это называем Сache line sharing
. Существует два типа разделения кэш-линий: true sharing
и false sharing
.
True sharing
(истинное разделение) – это когда потоки имеют доступ к одному и тому же объекту памяти, например, общей переменной или примитиву синхронизации. False sharing
(от лукавого) – это доступ к разным данным, но по каким-то причинам, оказавшимся в одной кэш-линии процессора. Сразу отметим, что и тот, и другой случай вредит производительности из-за необходимости аппаратной синхронизации кэш-памяти процессора, однако если первый случай часто неизбежен, то второй можно и нужно исключать.
Почему страдает производительность, поясним на примере. Допустим, мы обрабатываем последовательность структур данных, находящихся в очереди, в многопоточном режиме. Активные потоки один за одним вынимают следующую структуру из очереди и каким-либо образом обрабатывают ее, модифицируя данные. Что может произойти на аппаратном уровне, если, например, размер этой структуры небольшой и не превышает нескольких десятков байт?

Условия для возниконовения проблемы:
Два или более потока пишут в одну кэш-линию;
Один поток пишет, остальные читают из кэш-линии;
Один поток пишет, в остальных ядрах стработал HW prefetcher.
Может оказаться, что переменные в полях разных структур так расположились в памяти, что будучи считанными в L1 кэш процессора, находятся в одной кэш-линии, как на рисунке. При этом, если один из потоков модифицирует поле своей структуры, то вся кэш-линия в соответствии с cache coherency протоколом объявляется невалидной для остальных ядер процессора. Другой поток уже не сможет пользоваться своей структурой, несмотря на то, что она уже лежит в L1 кэше его ядра. В старых процессорах типа P4 в такой ситуации потребовалась бы долгая синхронизация с основной памятью, то есть модифицированные данные были бы отправлены в основную память и потом считаны в L1 кэш другого ядра. В текущем поколении процессоров (кодовое имя Sandy Bridge) синхронизационным механизмом используется общий кэш третьего уровня (или LLC – Last Level Cache), который является инклюзивным для подсистемы кэш-памяти и в котором располагаются все данные, находящиеся как в L2, так и в L1 всех ядер процессора. Таким образом, синхронизация происходит не с основной памятью, а с LLC, являющегося частью реализации протокола механизма когерентности кэшей, что намного быстрее. Но она все равно происходит, и на это требуется время, хотя и измеряемое всего несколькими десятками тактов процессора. А если данные в кэш-линии разделяются между потоками, которые выполняются в разных физических процессорах? Тогда уже придется синхнонизироваться между LLC разных чипов, а это намного дольше - уже сотни тактов. Теперь представим, что программа только и занимается тем, что в цикле обрабатывает поток данных, получаемых из какого-либо источника. Теряя сотни тактов на каждой итерации цикла, мы рискуем «уронить» свою производительность в разы.
Давайте посмотрим на следующий пример, специально упрощенный для того, чтобы было легче понять причины проблемы. Не сомневайтесь, в реальных приложениях такие же случаи встречаются очень часто, и в отличие от рафинированного примера, даже обнаружить существование проблемы не так просто. Ниже мы покажем, как с помощью профилировщика производительности быстро находить такие ситуации.
Потоковая функция в цикле пробегает по двум массивам float a[i] и b[i], перемножает их значения по индексу массива и складывает в локальные переменные потоков localSum. Для усиления эффекта эта операция делается несколько (ITERATIONS) раз.
< ITERATIONS; j++){ for (i = tid; i < MAXSIZE; i+= NUM_PROCS){ a[i] = i + a[i] * b[i]; localSum += a[i];}} }
Беда в том, что для разделения данных между потоками выбран способ перемежевания индексов цикла. То есть, если у нас работают два потока, первый будет обращаться к элементам массивов a и b, второй - к элементам a и b, первый - a и b, второй - a и b, и так далее. При этом элементы массива a[i] модифицируются потоками. Не трудно видеть, что в одну кэш-линию попадут 16 элементов массива, и потоки будут одновременно доступаться к соседним элементам, «сводя с ума» механизм синхрониции кэшей процессора.

Самое неприятное в том, что мы даже не заметим по работе программы существование этой проблемы. Она будет просто работать медленнее, чем может, вот и все. Как оценить эффективность программы с помощью профилировщика VTune Amplifier XE, я уже описывал в одном из постов на Хабре. Используя профиль General Exploration , о котором я там упоминал, можно увидеть описываемую проблему, которая будет «подсвечена» инструментом в результатах профилировки в колонке Contested Access . Эта метрика как раз и измеряет соотношение циклов, потраченых на синхронизацию кэшей процессора при их модификации потоками.

Если кому-то интересно, что стоит за этой метрикой, то во время комплексной профилировки инструмент среди других аппаратных счетчиков собирает и данные счетчика:
MEM_LOAD_UOPS_LLC_HIT_RETIRED.XSNP_HITM_PS
– Точный счетчик(PS) выполненной(RETIRED) операции(OUPS) загрузки(LOAD) данных(MEM), которые оказалиcь(HIT) в LLC и модифицированны(M). «Точный» счетчик означает, что данные, собранные таким счетчиком в семплировании, относятся к указателю инструкции (IP), следующему после инструкции, которая была той самой загрузкой, приведшей к синхронизации кэшей. Набрав статистику по этой метрике, мы можем с определенной точностью указать адрес инструкции, и, соответственно, строку исходного кода, где производилось чтение. VTune Amplifier XE может показать, какие потоки читали эти данные, а дальше мы уже должны сами сориентироваться, как реализован многопоточный доступ к данным и как исправить ситуацию.

Относительно нашего простого примера ситуацию исправить очень легко. Нужно просто разделить данные на блоки, при этом количество блоков будет равно количеству потоков. Кто-то может возразить: если массивы достаточно большие, то блоки могут просто не вместиться в кэш, и данные, загружаемые из памяти для каждого потока, будут вытеснять друг друга из кэша. Это будет верно в случае, если все данные блока используются постоянно, а не один раз. Например, при перемножении матриц мы пройдемся по элементам двумерного массива сначала по строкам, потом по столбцам. И если обе матрицы не помещаются в кэш (любого уровня), то они буду вытеснены, а повторный доступ к элементам потребует повторной загрузки из следующего уровня, что негативно влияет на производительность. В общем случае с матрицами применяется модифицированное перемножение матриц поблочно, при этом матрицы разбиваются на блоки, которые заведомо помещаются в заданную кэш-память, что значительно увеличивает производительность алгоритма.
Int work(void *pArg) { int j = 0, i = 0; int tid = (int) pArg; for (j = 0; j < ITERATIONS; j++){ chunks = MAXSIZE / NUM_PROCS; for (i = tid * chunks; i < (tid + 1) * chunks; i++){ a[i] = i + a[i] * b[i]; localSum += a[i];}} }
False sharing

No False sharing

Сравнение доступа потоков к элементам массива в случае False sharing и в исправленном коде
В нашем простом случае данные используются всего один раз, и даже если они будут вытеснены из кэш-памяти, они нам уже не понадобятся. А о том, чтобы данные обоих массивов a[i] и b[i], расположенные далеко друг от друга в адресном пространстве, вовремя оказались в кэше позаботится аппаратный prefetcher – механизм подкачки данных из основной памяти, реализованный в процессоре. Он отлично работает, если доступ к элементам массива последовательный.
В заключение, можно дать несколько общих рекомендаций, как избежать проблемы потери эффективности вычислений из-за разделения кэша между потоками. Из самого названия проблемы можно понять, что следует избегать кодирования, где потоки обращаются к общим данным очень часто. Если это true sharing мьютекса потоками, то возможно существует проблема излишней синхроницации, и следует пересмотреть подход к разделению ресурса, который защещен этим мьютексом. В общем случае старайтесь избегать глобальных и статических переменных, к которым требуется доступ из потоков. Используйте локальные переменные потоков.
Если вы работаете со структурами данных в многопоточном режиме, уделите внимание их размеру. Используйте «подкладки» (padding), чтобы нарастить размер структуры до 64 байт:
struct data_packet
{
int address;
int data;
int attribute;
int padding;
}
Выделяйте память под структуры по выровненному адресу:
__declspec(align(64)) struct data_packet sendpack
Используйте массивы структур вместо структур массивов:
data_packet sendpack;
вместо
struct data_packet
{
int address;
int data;
int attribute;
}
Как видно, в последнем случае потоки, модифицирующие одно из полей, приведут к запуску механизма синхронизации кэш-памяти.
Для объектов, аллоцируемых в динамической памяти с помощью malloc или new, cоздавайте локальные пулы памяти для потоков, либо используйте параллельные библиотеки, которые сами умеют это делать. Например, библиотека TBB содержит масштабируемые и выравнивающие аллокаторы , которые полезно использовать для масштабируемости многопоточных программ.
Ну и заключительный совет: не стоит бросаться решать проблему, если она не сильно влияет на общую производительность приложения. Всегда оценивайте потенциальный выигрыш, который вы получите в результате затрат на оптимизацию вашего кода. Используйте инструменты профилировки, чтобы оценить этот выигрыш.
P.S. Попробуйте мой примерчик, и расскажите, на сколько процентов увеличилось быстродействие теста на вашей платформе.
Теги: Добавить метки