Как заставить DLP-систему работать. Как работают DLP-системы: разбираемся в технологиях предотвращения утечки информации
О проблеме Сегодня, информационные технологии являются важной составляющей любой современной организации. Говоря образно, информационные технологии - это сердце предприятия, которое поддерживает работоспособность бизнеса и повышает его эффективность и конкурентоспособность в условиях современной, жесткой конкуренции.Системы автоматизации бизнес-процессов, такие как документооборот, CRM -системы, ERP -системы, системы многомерного анализа и планированияпозволяют оперативно собирать информацию, систематизировать и группировать ее,ускоряя процессы принятия управленческих решений и обеспечивая прозрачность бизнеса и бизнес-процессов для руководства и акционеров.Становится очевидным, что большое количество стратегических, конфиденциальных и персональных данных является важным информационным активом предприятия, и последствия утечки этой информации скажутся на эффективности деятельности организации.Использование традиционных на сегодня мер безопасности,таких как антивирусы и фаерволлы выполняют функции защиты информационных активов от внешних угроз, но не каким образом не обеспечивают защиту информационных активов от утечки, искажения или уничтожения внутренним злоумышленником.Внутренние же угрозы информационной безопасности могут оставаться игнорируемыми или в ряде случаев незамеченными руководством ввиду отсутствия понимания критичности этих угроз для бизнеса.Именно по этой причине защита конфиденциальных данных так важна уже сегодня.О решении Защита конфиденциальной информации от утечки является важной составляющей комплекса информационной безопасности организации. Решить проблему случайных и умышленных утечек конфиденциальных данных, призваны DLP-системы (система защиты данных отутечки).
Комплексная система защиты данных от утечек (DLP-система) представляют собой программный, либо программно-аппаратный комплекс, предотвращающий утечку конфиденциальных данных.
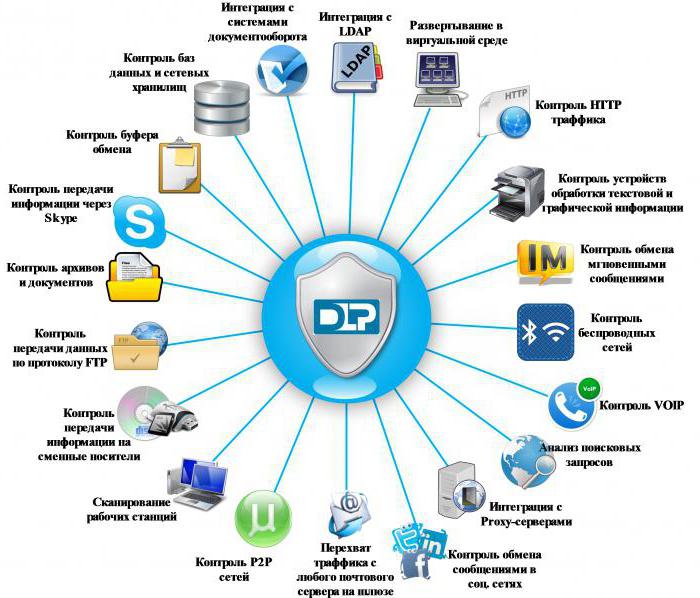
Осуществляется DLP-системой при помощи использования следующих основных функций:
- Фильтрация трафика по всем каналам передачи данных;
- Глубокий анализ трафика на уровне контента и контекста.
Data-in-Motion – данные, передаваемые по сетевым каналам:
- Web (HTTP/HTTPS протоколы);
- Интернет – мессенджеры (ICQ, QIP, Skype, MSN и т.д.);
- Корпоративная и личная почта(POP, SMTP, IMAP и т.д.);
- Беспроводные системы (WiFi, Bluetooth, 3G и т.д.);
- FTP – соединения.
- Серверах;
- Рабочих станциях;
- Ноутбуках;
- Системах хранения данных (СХД).
Меры, направленные на предотвращение утечек информации состоят из двух основных частей: организационных и технических.
Защита конфиденциальной информации включает в себя организационные меры по поиску и классификации имеющихся в компании данных. В процессе классификации данные разделяются на 4 категории:
- Секретная информация;
- Конфиденциальная информация;
- Информация для служебного пользования;
- Общедоступная информация.
В DLP-системах конфиденциальная информация может определяться по ряду различных признаков, а также различными способами, например:
- Лингвистический анализ информации;
- Статистический анализ информации;
- Регулярные выражения (шаблоны);
- Метод цифровых отпечатков и т.д.
Технические меры:
Защита конфиденциальной информации при помощи технических мер основана на использование функционала и технологий системы по защите данных отутечек. В состав DLP-системы входят два модуля: хост модуль и сетевой модуль.
Хост модули устанавливаются на рабочие станции пользователей и обеспечивают контроль действий производимых пользователем в отношении классифицированных данных (конфиденциальной информации). Кроме этого модуль хоста позволяет отслеживать активность пользователя по различным параметрам,например время, проведенное в Интернет, запускаемые приложения, процессы и пути перемещения данных и т.д.
Сетевой модуль осуществляет анализ передаваемой по сети информации и контролирует трафик выходящей за пределы защищаемой информационной системы. В случае обнаружения в передаваемой трафике конфиденциальной информации сетевой модуль пресекает передачу данных.
Что даст внедрение DLP-системы?
После внедрения системы защиты данных от утечки компания получит:
- Защиту информационных активов и важной стратегической информации компании;
- Структурированные и систематизированные данные в организации;
- Прозрачности бизнеса и бизнес-процессов для руководства и служб безопасности;
- Контроль процессов передачи конфиденциальных данных в компании;
- Снижение рисков связанных с потерей, кражей и уничтожением важной информации;
- Защита от вредоносного ПО попадающего в организацию изнутри;
- Сохранение и архивация всех действий связанных с перемещением данных внутри информационной системы;
- Контроль присутствия персонала на рабочем месте;
- Экономия Интернет-трафика;
- Оптимизация работы корпоративной сети;
- Контроль используемых пользователем приложений;
- Повышение эффективности работы персонала.
(Data Loss Prevention)
Системы контроля действий пользователей, система защиты конфиденциальных данных от внутренних угроз.
DLP-системы применяются для обнаружения и предотвращения передачи конфиденциальных данных на разных этапах. (при перемещении, использовании и хранении). DLP-система позволяет:
Контроллировать работу пользователей, не давая бесконтрольно тратить рабочее время в личных целях.
Автоматически, незаметно для пользователя, записывать все действия, включая отправляемые и принимаемые сообщения электройнной почты, общение в чатах и системах мгновенного обмена сообщениями, социальных сетях, посещаемые веб-сайты, набранные на клавиатуре данные, переданные, напечатанные и сохранённые файлы и т. д.
Контроллировать использование компьютерных игр на рабочем месте и учитывать количество рабочего времени, потраченного на компьютерные игры.
Контроллировать сетевую активность пользователей, учитывать объёмы сетевого трафика
Контроллировать копирование документов на различные носители (съемные носители, жесткие диски, сетевые папки и т. д.)
Контроллировать сетевую печать пользователя
Фиксировать запросы пользователей поисковым машинам и т. д.
Data-in-motion - данные в движении - сообщения email, передача веб-трафика, файлов и т. д.
Data-in-rest - хранящиеся данные - информация на рабочих станциях, файловых серверах, usb-устройствах и т. д.
Data-in-use - данные в использовании - информация, обрабатываемая в данный момент.
Архитектура DLP решений у разных разработчиков может различаться, но в целом выделяют 3 основных веяния:
Перехватчики и контроллеры на разные каналы передачи информации. Перехватчики анализируют проходящие потоки информации, исходящие с периметра компании, обнаруживают конфиденциальные данные, классифицируют информацию и передают для обработки возможного инцидента на управляющий сервер. Контроллеры для обнаружения хранимых данных запускают процессы обнаружения в сетевых ресурсах конфиденциальной информации. Контроллеры для операций на рабочих станциях распределяют политики безопасности на оконечные устройства (компьютеры), анализируют результаты деятельности сотрудников с конфиденциальной информацией и передают данные возможного инцедента на управляющий сервер.
Агентские программы, устанавливаемые на оконечные устройства: замечают конфиденциальные данные в обработке и следят за соблюдением таких правил, как сохранение на сменный носитель информации, отправке, распечатывании, копировании через буфер обмена.
Центральный управляющий сервер - сопоставляет поступающие с перехватчиков и контроллеров сведения и предоставляет интерфейс проработки инцидентов и построения отчётности.
В решениях DLP имеется широкий набор комбинированных методов обнаружения информации:
Цифровые отпечатки документов и их частей
Цифровые отпечатки баз данных и другой структурированной информации, которую важно защитить от распространения
Статистические методы (повышение чувствительности системы при повторении нарушений).
При эксплуатации DLP-систем характерно циклическое выполнение нескольких процедур:
Обучение системы принципам классификации информации.
Ввод правил реагирования в привязке к категории обнаруживаемой информации и групп сотрудников, контроль действий которых должен осуществляться. Выделяются доверенные пользователи.
Выполнение DLP-системой операции контроля (система анализирует и нормализует информацию, выполняет сопоставление с принципами обнаружения и классификации данных, и при обнаружении конфиденциальной информации, система сопоставляет с существующими политиками, назначенными на обнаруженную категорию информации и, при необходимости, создаёт инцидент)
Обработка инцидентов (например проинформировать, приостановить или заблокировать отправку).
Особенности создания и эксплуатации VPN с точки зрения безопасности
Варианты построения VPN:
На базе сетевых операционных систем
На базе маршрутизаторов
На базе МСЭ
На базе специализированного программно-аппаратного обеспечения
На базе специализированного ПО
Для корректной и безопасной работы VPN необходимо понимать основы взаимодействия VPN и межсетевых экранов:
VPN способны создавать сквозные связующие тунели, проходящие через сетевой периметр, а потому крайне проблемные в плане контроля доступа со стороны межсетевого экрана, которому трудно анализировать зашифрованый трафик.
Благодаря своим функциям шифрования передаваемых данных, VPN можно использовать для обхода IDS-систем, не способных обнаруживать вторжения со стороны зашифрованных каналов связи.
В зависимости от сетевой архитектуры, крайне важная функция трансляции сетевых адресов (NAT - network adress translation) может оказаться несовместима с некоторыми реализациями VPN и т. д.
По сути, во время принятия решений о внедрении VPN-компонентов в сетевую архитектуру, администратор может либо выбрать VPN в качестве обособленного внешнего устройства, либо выбрать интеграцию VPN в МСЭ, для обеспечения обеих функций одной системы.
Внутри демилитаризованной зоны, между МСЭ и граничным маршрутизатором
Вутри подзащитной сети на сетевых адаптерах МСЭ
Внутри экранированной сети, позади МСЭ
Параллельно с МСЭ, на точке входа в подзащитную сеть.
При установлении защищённого соединения между VPN-устройствами (аутентификация, обмен ключами и т. д.)
Задержки, связанные с зашифрованием и расшифрованием защищаемых данных, а так же преобразованиями, необходимыми для контроля их целостности
Задержки, связанные с добавлением нового заголовка передаваемым пакетам
МСЭ + Обособленный VPN. Варианты размещения VPN:
МСЭ + VPN, размещенные как единое целое - подобное интегрированное решение более удобно при техническом сопровождении, чем предыдущий вариант, не вызывает проблем, связанных с NAT (трансляцией сетевых адресов) и обеспечивает более надёжный доступ к данным, за который отвечает МСЭ. Недостатком интегрированного решения является большая изначальная стоимость покупки такого средства, а так же ограниченность вариантов оптимизации соответствующих VPN и Брендмауэр-компонент (то есть максимально удовлетворяющие запросам реализации МСЭ могут оказаться не приспособленными к построению на их основе VPN-компонентов. VPN может оказывать существенное воздействие на производительность сети и задержки могут возникать на следующих этапах:
Безопасность электронной почты
Основные почтовые протоколы: (E)SMTP, POP, IMAP.
SMTP - simple mail transfer protocol, 25 порт TCP, нет аутентификации. Extended SMTP - добавлена аутентификация клиентов.
POP - post Office Protocol 3 - получение почты с сервера. Аутентификация в открытом виде. APOP - с возможностью аутентификации.
IMAP - internet message access protocol - незашифрованный почтовый протокол, который комбинирует свойства POP3 и IMAP. Позволяет работать напрямую с почтовым ящиком, без необходимости загрузки писем на компьютер.
Из-за отсутствия каких-либо нормальных средств шифровки информации, решили использовать SSL для шифровки данных этих протоколов. Отсюда появлились следующие разновидности:
POP3 SSL - 995 порт, SMTP SSL (SMTPS) 465 порт, IMAP SSL (IMAPS) - 993 порт, всё TCP.
Злоумышленник, работающий с системой электронной почты, может преследовать следующие цели:
Перехват паролей в POP и IMAP сеансах, в результате чего злоумышленник может получать и удалять почту без ведома пользователя
Перехват паролей в SMTP сеансах - в результате чего злоумышленник может быть незаконно авторизован для отправки почты через данный сервер
Атака на компьютер пользователя посредством рассылки почтовых вирусов, отправка поддельных писем (подделка адреса отправителя в SMTP - тривиальная задача), чтение чужих писем.
Атака на почтовый сервер средствами электронной почты с целью проникновения в его операционную систему или отказ в обслуживании
Использование почтового сервера в качестве ретранслятора при рассылке непрошенных сообщений (спама)
Перехват паролей:
Для решения проблем безопасности с протоколами POP, IMAP и SMTP, чаще всего используется протокол SSL, позволяющий зашифровать весь сеанс связи. Недостаток - SSL - ресурсоёмкий протокол, может существенно замедлить связь.
Спам и борьба с ним
Виды мошеннического спама:
Лотерея - восторженное уведомление о выигрышах в лотереях, в которых получатель сообщения не участвовал. Всё, что нужно - посетить соответствующий сайт и ввести там номер своего счёта и пин-код карты, необходимых якобы для оплаты услуг доставки.
Аукционы - заключается данный вид обмана в отсутствии товара, который продают жулики. Расплатившись, клиент ничего не получает.
Фишинг - письмо, содержащее ссылку на некоторый ресурс, где от вас желают предоставления данных и т. д. Выманивание у доверчивых или невнимательных пользователей персональных и конфиденциальных данных. Мошенники рассылают массу писем, как правило замаскированных под официальные письма различных учреждений, содержащих ссылки, ведущие на сайты-ловушки, визуально копирующие сайты банков, магазинов и др. организаций.
Почтовое жульничество - набор персонала для некоторой фирмы якобы нуждающейся в представителе в какой-либо стране, способного взять на себя заботы о пересылке товаров или переводе денег иностранной компании. Как правило, здесь скрываются схемы по отмыванию денег.
Нигерийские письма - просят внести небольшую сумму перед получением денег.
Письма счастья
Спам бывает массовым и целевым.
У массового спама отсутствуют конкретные цели и используется мошеннические методы социальной инженерии против множества людей.
Целевой спам - техника, направленная на конкретное лицо или организацию, при которой злоумышленник выступает от имени директора, администратора или иного сотрудника той организации, в которой работает жертва или злоумышленник представляет компанию, с которой у целевой организации сложились доверительные отношения.
Сбор адресов осуществляется подбором по словарям имён собственных, красивых слов, частое сочетание слово-цифра, методом аналогии, сканированием всех доступных источников информации (чаты, форумы и т. д.), воровством БД и т. д.
Полученные адреса верифицируются (проверяются, что действующие), путём пробной рассылки сообщения, помещением в текст сообщения, уникальной ссылки на картинку со счётчиком загрузок или ссылка «отписаться от спам-сообщений».
В дальнейшем спам рассылается либо напрямую с арендованных серверов, либо с ошибочно сконфигурированных легальных почтовых сервисов, либо путём скрытой установки на компьютер пользователя злонамеренного ПО.
Злоумышленник усложняет работу антиспам-фильтров путём внесения случайных текстов, шума или невидимых текстов, с помощью графических писем или изменяющихся графических писем, фрагментированные изображения, в том числе использование анимации, префразировка текстов.
Методы борьбы со спамом
Существует 2 основных метода фильтрации спама:
Фильтрация по формальным признакам почтового сообщения
Фильтрация по содержанию
Фрагментация по спискам: чёрным, белым и серым. Серые списки - метод временного блокирования сообщений с неизвестными комбинациями почтового адреса и ip-адреса сервера-отправителя. Когда первая попытка заканчивается временным отказом (как правило, программы спамеров повторную посылку письма не осуществляют). Недостатком способа является возможный большой временной интервал между отправлением и получением легального сообщения.
Проверка, было ли письмо отправлено с настоящего или ложного (поддельного) почтового сервера из указанного в сообщении домена.
«Обратный звонок» (callback) - при получении входящего соединения, сервер-получатель приостанавливает сессию и имитирует рабочую сессию с сервером-отправителем. Если попытка не удалась, приостановленное соединение разрывается без дальнейшей обработки.
Фильтрация по формальным признакам письма: адреса отправителя и получателя, размер, наличие и количество вложений, ip-адрес отправителя и т. д.
Формальный метод
Распознавание по содержанию письма - проверяется наличие в письме признаков спамерского содержания: определённого набора и распределение по письму специфических словосочетаний.
Распознавание по образцам писем (сигнатурный метод фильтрации, включающий в себя графические сигнатуры)
Байесовская фильтрация - фильтрация строго по словам. При проверке пришедшего письма, вычисляется вероятность того, что оно спам, на основании обработки текста, включающей в себя вычисления усреднённого «веса» всех слов данного письма. Отнесение письма к спаму или не спаму, производится по тому, превышает ли его вес некоторую планку, заданную пользователем. После принятия решения по письму, в базе данных обновляются «веса» для вошедших в неё слов.
Лингвистические методы - работающие с содержанием письма
Аутентификация в компьютерных системах
Процессы аутентификации могут быть разделены на следующие категории:
Но основе знания чего-либо (PIN, пароль)
На основе обладания чем-либо (смарт-карта, usb-ключ)
Не основе неотъемлимых характеристик (биометрические характеристики)
Типы аутентификации:
Простая аутентификация, использующая пароли
Строгая аутентификация на основе использования многофакторных проверок и криптографических методов
Биометрическая аутентификация
Основными атаками на протоколы аутентификации являются:
«Маскарад» - когда пользователь пытается выдать себя за другого пользователя
Повторная передача - когда перехваченный пароль пересылается от имени другого пользователя
Принудительная задержка
Для предотвращения таких атак сипользуются следующие приёмы:
Механизмы типа запрос-ответ, метки времени, случайные числа, цифровые подписи и т. д.
Привязка результата аутентификации к последующим действиям пользователей в рамках системы.
Периодическое выполнение процедур аутентификации в рамках уже установленного сеанса связи.
Аутентификация на основе многоразовых паролей
Аутентификация на основе одноразовых паролей - OTP (one time password) - одноразовые пароли действительны только для одного входа в систему и могут генерироваться с помощью OTP токена. Для этого используется секретный ключ пользователя, размещенный как внутри OTP токена, так и на сервере аутентификации.
Простая аутентификация
Односторонней
Двухсторонней
Трёхсторонней
Строгая аутентификация в её ходе доказывающая сторона доказывает свою подлинность проверяющей стороне, демонстрируя знание некоторого секрета. Бывает:
Может проводиться на основе смарт-карт или usb-ключей или криптографией.
Строгая аутентификация может быть реализована на основе двух- и трёхфакторного процесса проверки.
В случае двухфакторной аутентификации, пользователь должен доказать, что он знает пароль или пин-код и имеет определённый персональных идентификатор (смарт-карту или usb-ключ).
Трёхфакторная аутентификация подразумевает, что пользователь предъявляет еще один тип идентификационных данных, например, биометрические данные.
Строгая аутентификация, использующая криптографические протоколы может опираться на симметричное шифрование и асимметричное, а также на хеш-функции. Доказывающая сторона доказывает знание секрета, но сам секрет при этом не раскрывается. Используются одноразовые параметры (случайные числа, метки времени и номера последовательностей), позволяющие избежать повтора пеердачи, обеспечить уникальность, однозначность и временные гарантии передаваемых сообщений.
Биометрическая аутентификация пользователя
В качестве наиболее часто используемых биометрических признаков, используются:
Отпечатки пальцев
Рисунок вен
Геометрия руки
Радужная оболочка
Геометрия лица
Комбинации вышеперечисленного
Управление доступом по схеме однократного входа с авторизацией Single Sign-On (SSO)
SSO даёт возможность пользователю корпоративной сети при их входе в сеть пройти только одну аутентификацию, предъявив только один раз пароль или иной требуемый аутентификатор и затем, без дополнительной аутентификации, получить доступ ко всем авторизованным сетевым ресурсам, которые нужны для выполнения работы. Активно применяются такие цифровые средства аутентификации как токены, цифровые сертификаты PKI, смарт-карты и биометрические устройства. Примеры: Kerberos, PKI, SSL.
Реагирование на инциденты ИБ
Среди задач, стоящих перед любой системой управления ИБ, можно выделить 2 наиболее значимые:
Предотвращение инцидентов
В случае их наступления, своевременная и корректная ответная реакция
Первая задача в большинстве случаев основывается на закупке разнообразных средств обеспечения ИБ.
Вторая задача находится в зависимости от степени подготовленности компании к подобного рода событиям:
Наличие подготовленной группы реагирования на инцидент ИБ с уже заранее распределёнными ролями и обязанностями.
Наличие продуманной и взаимосвязанной документации по порядку управления инцидентами ИБ, в частности, осуществлению реагирования и расследования выявленных инцидентов.
Наличие заготовленных ресурсов для нужд группы реагирования (средств коммуникации, ..., сейфа)
Наличие актуальной базы знаний по произошедшим инцидентам ИБ
Высокий уровень осведомлённости пользователей в области ИБ
Квалифицированность и слаженность работы группы реагирования
Процесс управления инцидентами ИБ состоит из следующих этапов:
Подготовка – предотвращение инцидентов, подготовка группы реагирования, разработка политик и процедур и т.д.
Обнаружение – уведомление от системы безопасности, уведомление от пользователей, анализ журналов средств безопасности.
Анализ – подтверждение факта наступления инцидента, сбор доступной информации об инциденте, определение пострадавших активов и классификация инцидента по безопасности и приоритетности.
Реагирование – остановка инцидента и сбор доказательств, принятие мер по остановке инцидента и сохранение доказательной информации, сбор доказательной информации, взаимодействие с внутренними подразделениями, партнёрами и пострадавшими сторонами, а так же привлечение внешних экспертных организаций.
Расследование – расследование обстоятельств инцидентов информационной безопасности, привлечение внешних экспертных организаций и взаимодействие со всеми пострадавшими сторонами, а так же с правоохранительными органами и судебными инстанциями.
Восстановление – принятие мер по закрытию уязвимостей, приведших к возникновению инцидента, ликвидация последствий инцидента, восстановление работоспособности затронутых сервисов и систем. Оформление страхового извещения.
Анализ эффективности и модернизация – анализ произошедшего инцидента, анализ эффективности и модернизация процесса расследования инцидентов ИБ и сопутствующих документов, частных инструкций. Формирование отчёта о проведении расследования и необходимости модернизации системы защиты для руководства, сбор информации об инциденте, добавление в базу знаний и помещение данных об инциденте на хранение.
Перед эффективной системой управления инцидентами ИБ стоят следующие цели:
Обеспечение юридической значимости собираемой доказательной информации по инцидентам ИБ
Обеспечение своевременности и корректности действий по реагированию и расследованию инцидентов ИБ
Обеспечение возможности выявления обстоятельств и причин возникновения инцидентов ИБ с целью дальнейшей модернизации системы информационной безопасности
Обеспечение расследования и правового сопровождения внутренних и внешних инцидентов ИБ
Обеспечение возможности преследования злоумышленников и привлечение их к ответственности, предусмотренной законодательством
Обеспечение возможности возмещения ущерба от инцидента ИБ в соответствии с законодательством
Система управления инцидентами ИБ в общем случае взаимодействует и интегририруется со следующими системами и процессами:
Управление ИБ
Управление рисками
Обеспечение непрерывности бизнеса
Интеграция выражается в согласованности документации и формализации порядка взаимодействия между процессами (входной, выходной информации и условий перехода).
Процесс управления инцидентами ИБ довольно сложен и объёмен. Требует накопления, обработки и хранения огромного количества информации, а так же выполнения множества параллельных задач, поэтому на рынке представлено множество средств, позволяющих автоматизировать те или иные задачи, например, так называемые SIEM-системы (security information and event management).
Chief Information Officer (CIO) – директор по информцаионным технологиям
Chief Information Security Officer (CISO) – руководитель отдела ИБ, директор по информационной безопасности
Основная задача SIEM-систем не просто собирать события из разных источников, но автоматизировать процесс обнаружения инцидентов с документированием в собственном журнале или внешней системе, а так же своевременно информировать о событии. Перед SIEM-системой ставятся следующие задачи:
Консолидация и хранение журналов событий от различных источников – сетевых устройств, приложений, журналов ОС, средств защиты
Представление инструментов для анализа событий и разбора инцидентов
Корреляция и обработка по правилам произошедших событий
Автоматическое оповещение и управление инцидентами
SIEM-системы способны выявлять:
Сетевые атаки во внутреннем и внешнем периметрах
Вирусные эпидемии или отдельные вирусные заражения, неудалённые вирусы, бэкдоры и трояны
Попытки несанкционированного доступа к конфиденциальной информации
Ошибки и сбои в работе ИС
Уязвимости
Ошибки в конфигурации, средствах защиты и информационных системах.
Основные источники SIEM
Антивирусная защита
Сканеры уязвимостей
Системы для учёта рисков, критичности угрозы и приоретизация инцидентов
Прочие системы защиты и контроля политик ИБ:
DLP-системы
Устройства контроля доступа и т.д.
Данные контроля доступа и аутентификации
Журналы событий серверов и рабочих станций
Сетевое активное оборудование
Системы инвентаризации
Системы учёта трафика
Наиболее известные SIEM-системы:
QRadar SIEM (IBM)
КОМРАД (ЗАО «НПО «ЭШЕЛОН»»)
Если быть достаточно последовательным в определениях, то можно сказать, что информационная безопасность началась именно с появления DLP-систем. До этого все продукты, которые занимались «информационной безопасностью», на самом деле защищали не информацию, а инфраструктуру - места хранения, передачи и обработки данных. Компьютер, приложение или канал, в которых находится, обрабатывается или передается конфиденциальная информация, защищаются этими продуктами точно так же, как и инфраструктура, в которой обращается совершенно безобидная информация. То есть именно с появлением DLP-продуктов информационные системы научились наконец-то отличать конфиденциальную информацию от неконфиденциальной. Возможно, с встраиванием DLP-технологий в информационную инфраструктуру компании смогут сильно сэкономить на защите информации - например, использовать шифрование только в тех случаях, когда хранится или передается конфиденциальная информация, и не шифровать информацию в других случаях.
Однако это дело будущего, а в настоящем данные технологии используются в основном для защиты информации от утечек. Технологии категоризации информации составляют ядро DLP-систем. Каждый производитель считает свои методы детектирования конфиденциальной информации уникальными, защищает их патентами и придумывает для них специальные торговые марки. Ведь остальные, отличные от этих технологий, элементы архитектуры (перехватчики протоколов, парсеры форматов, управление инцидентами и хранилища данных) у большинства производителей идентичны, а у крупных компаний даже интегрированы с другими продуктами безопасности информационной инфраструктуры. В основном для категоризации данных в продуктах по защите корпоративной информации от утечек используются две основных группы технологий - лингвистический (морфологический, семантический) анализ и статистические методы (Digital Fingerprints, Document DNA, антиплагиат). Каждая технология имеет свои сильные и слабые стороны, которые определяют область их применения.
Лингвистический анализ
Использование стоп-слов («секретно», «конфиденциально» и тому подобных) для блокировки исходящих электронных сообщений в почтовых серверах можно считать прародителем современных DLPсистем. Конечно, от злоумышленников это не защищает - удалить стоп-слово, чаще всего вынесенное в отдельный гриф документа, не составляет труда, при этом смысл текста нисколько не изменится.
Толчок в разработке лингвистических технологий был сделан в начале этого века создателями email-фильтров. Прежде всего, для защиты электронной почты от спама. Это сейчас в антиспамовских технологиях преобладают репутационные методы, а в начале века шла настоящая лингвистическая война между снарядом и броней - спамерами и антиспамерами. Помните простейшие методы для обмана фильтров, базирующихся на стоп-словах? Замена букв на похожие буквы из других кодировок или цифры, транслит, случайным образом расставленные пробелы, подчеркивания или переходы строк в тексте. Антиспамеры довольно быстро научились бороться с такими хитростями, но тогда появился графический спам и прочие хитрые разновидности нежелательной корреспонденции.
Однако использовать антиспамерские технологии в DLP-продуктах без серьезной доработки невозможно. Ведь для борьбы со спамом достаточно делить информационный поток на две категории: спам и не спам. Метод Байеса, который используется при детектировании спама, дает только бинарный результат: «да» или «нет». Для защиты корпоративных данных от утечек этого недостаточно - нельзя просто делить информацию на конфиденциальную и неконфиденциальную. Нужно уметь классифицировать информацию по функциональной принадлежности (финансовая, производственная, технологическая, коммерческая, маркетинговая), а внутри классов - категоризировать ее по уровню доступа (для свободного распространения, для ограниченного доступа, для служебного использования, секретная, совершенно секретная и так далее).
Большинство современных систем лингвистического анализа используют не только контекстный анализ (то есть в каком контексте, в сочетании с какими другими словами используется конкретный термин), но и семантический анализ текста. Эти технологии работают тем эффективнее, чем больше анализируемый фрагмент. На большом фрагменте текста точнее проводится анализ, с большей вероятностью определяется категория и класс документа. При анализе же коротких сообщений (SMS, интернет-пейджеры) ничего лучшего, чем стоп-слова, до сих пор не придумано. Автор столкнулся с такой задачей осенью 2008 года, когда с рабочих мест многих банков через мессенджеры пошли в Сеть тысячи сообщений типа «нас сокращают», «отберут лицензию», «отток вкладчиков», которые нужно было немедленно заблокировать у своих клиентов.
Достоинства технологии
Достоинства лингвистических технологий в том, что они работают напрямую с содержанием документов, то есть им не важно, где и как был создан документ, какой на нем гриф и как называется файл - документы защищаются немедленно. Это важно, например, при обработке черновиков конфиденциальных документов или для защиты входящей документации. Если документы, созданные и использующиеся внутри компании, еще как-то можно специфическим образом именовать, грифовать или метить, то входящие документы могут иметь не принятые в организации грифы и метки. Черновики (если они, конечно, не создаются в системе защищенного документооборота) тоже могут уже содержать конфиденциальную информацию, но еще не содержать необходимых грифов и меток.
Еще одно достоинство лингвистических технологий - их обучаемость. Если ты хоть раз в жизни нажимал в почтовом клиенте кнопку «Не спам», то уже представляешь клиентскую часть системы обучения лингвистического движка. Замечу, что тебе совершенно не нужно быть дипломированным лингвистом и знать, что именно изменится в базе категорий - достаточно указать системе ложное срабатывание, все остальное она сделает сама.
Третьим достоинством лингвистических технологий является их масштабируемость. Скорость обработки информации пропорциональна ее количеству и абсолютно не зависит от количества категорий. До недавнего времени построение иерархической базы категорий (исторически ее называют БКФ - база контентной фильтрации, но это название уже не отражает настоящего смысла) выглядело неким шаманством профессиональных лингвистов, поэтому настройку БКФ можно было смело отнести к недостаткам. Но с выходом в 2010 сразу нескольких продуктов-«автолингвистов» построение первичной базы категорий стало предельно простым - системе указываются места, где хранятся документы определенной категории, и она сама определяет лингвистические признаки этой категории, а при ложных срабатываниях - самостоятельно обучается. Так что теперь к достоинствам лингвистических технологий добавилась простота настройки.
И еще одно достоинство лингвистических технологий, которое хочется отметить в статье - возможность детектировать в информационных потоках категории, не связанные с документами, находящимися внутри компании. Инструмент для контроля содержимого информационных потоков может определять такие категории, как противоправная деятельность (пиратство, распространение запрещенных товаров), использование инфраструктуры компании в собственных целях, нанесение вреда имиджу компании (например, распространение порочащих слухов) и так далее.
Недостатки технологий
Основным недостатком лингвистических технологий является их зависимость от языка. Невозможно использовать лингвистический движок, разработанный для одного языка, в целях анализа другого. Это было особенно заметно при выходе на российский рынок американских производителей - они были не готовы столкнуться с российским словообразованием и наличием шести кодировок. Недостаточно было перевести на русский язык категории и ключевые слова - в английском языке словообразование довольно простое, а падежи выносятся в предлоги, то есть при изменении падежа меняется предлог, а не само слово. Большинство существительных в английском языке становятся глаголами без изменений слова. И так далее. В русском все не так - один корень может породить десятки слов в разных частях речи.
В Германии американских производителей лингвистических технологий встретила другая проблема - так называемые «компаунды», составные слова. В немецком языке принято присоединять определения к главному слову, в результате чего получаются слова, иногда состоящие из десятка корней. В английском языке такого нет, там слово - последовательность букв между двумя пробелами, соответственно английский лингвистический движок оказался неспособен обработать незнакомые длинные слова.
Справедливости ради следует сказать, что сейчас эти проблемы во многом американскими производителями решены. Пришлось довольно сильно переделать (а иногда и писать заново) языковой движок, но большие рынки России и Германии наверняка того стоят. Также сложно обрабатывать лингвистическими технологиями мультиязычные тексты. Однако с двумя языками большинство движков все-таки справляются, обычно это национальный язык + английский - для большинства бизнес-задач этого вполне достаточно. Хотя автору встречались конфиденциальные тексты, содержащие, например, одновременно казахский, русский и английский, но это скорее исключение, чем правило.
Еще одним недостатком лингвистических технологий для контроля всего спектра корпоративной конфиденциальной информации является то, что не вся конфиденциальная информация находится в виде связных текстов. Хотя в базах данных информация и хранится в текстовом виде, и нет никаких проблем извлечь текст из СУБД, полученная информация чаще всего содержит имена собственные - ФИО, адреса, названия компаний, а также цифровую информацию - номера счетов, кредитных карт, их баланс и прочее. Обработка подобных данных с помощью лингвистики много пользы не принесет. То же самое можно сказать о форматах CAD/CAM, то есть чертежах, в которых зачастую содержится интеллектуальная собственность, программных кодах и медийных (видео/аудио) форматах - какие-то тексты из них можно извлечь, но их обработка также неэффективна. Еще года три назад это касалось и отсканированных текстов, но лидирующие производители DLP-систем оперативно добавили оптическое распознавание и справились с этой проблемой.
Но самым большим и наиболее часто критикуемым недостатком лингвистических технологий является все-таки вероятностный подход к категоризации. Если ты когда-нибудь читал письмо с категорией «Probably SPAM», то поймешь, о чем я. Если такое творится со спамом, где всего две категории (спам/не спам), можно себе представить, что будет, когда в систему загрузят несколько десятков категорий и классов конфиденциальности. Хотя обучением системы можно достигнуть 92-95% точности, для большинства пользователей это означает, что каждое десятое или двадцатое перемещение информации будет ошибочно причислено не к тому классу со всеми вытекающими для бизнеса последствиями (утечка или прерывание легитимного процесса).
Обычно не принято относить к недостаткам сложность разработки технологии, но не упомянуть о ней нельзя. Разработка серьезного лингвистического движка с категоризацией текстов более чем по двум категориям - наукоемкий и довольно сложный технологически процесс. Прикладная лингвистика - быстро развивающаяся наука, получившая сильный толчок в развитии с распространением интернет-поиска, но сегодня на рынке присутствуют единицы работоспособных движков категоризации: для русского языка их всего два, а для некоторых языков их просто еще не разработали. Поэтому на DLP-рынке существует лишь пара компаний, которые способны в полной мере категоризировать информацию «на лету». Можно предположить, что когда рынок DLP увеличится до многомиллиардных размеров, на него с легкостью выйдет Google. С собственным лингвистическим движком, оттестированным на триллионах поисковых запросов по тысячам категорий, ему не составит труда сразу отхватить серьезный кусок этого рынка.
Статистические методы
Задача компьютерного поиска значимых цитат (почему именно «значимых» - немного позже) заинтересовала лингвистов еще в 70-х годах прошлого века, если не раньше. Текст разбивался на куски определенного размера, с каждого из которых снимался хеш. Если некоторая последовательность хешей встречалась в двух текстах одновременно, то с большой вероятностью тексты в этих областях совпадали.
Побочным продуктом исследований в этой области является, например, «альтернативная хронология» Анатолия Фоменко, уважаемого ученого, который занимался «корреляциями текстов» и однажды сравнил русские летописи разных исторических периодов. Удивившись, насколько совпадают летописи разных веков (более чем на 60%), в конце 70-х он выдвинул теорию, что наша хронология на несколько веков короче. Поэтому, когда какая-то выходящая на рынок DLP-компания предлагает «революционную технологию поиска цитат», можно с большой вероятностью утверждать, что ничего, кроме новой торговой марки, компания не создала.
Статистические технологии относятся к текстам не как к связной последовательности слов, а как к произвольной последовательности символов, поэтому одинаково хорошо работают с текстами на любых языках. Поскольку любой цифровой объект - хоть картинка, хоть программа - тоже последовательность символов, то те же методы могут применяться для анализа не только текстовой информации, но и любых цифровых объектов. И если совпадают хеши в двух аудиофайлах - наверняка в одном из них содержится цитата из другого, поэтому статистические методы являются эффективными средствами защиты от утечки аудио и видео, активно применяющиеся в музыкальных студиях и кинокомпаниях.
Самое время вернуться к понятию «значимая цитата». Ключевой характеристикой сложного хеша, снимаемого с защищаемого объекта (который в разных продуктах называется то Digital Fingerprint, то Document DNA), является шаг, с которым снимается хеш. Как можно понять из описания, такой «отпечаток» является уникальной характеристикой объекта и при этом имеет свой размер. Это важно, поскольку если снять отпечатки с миллионов документов (а это объем хранилища среднего банка), то для хранения всех отпечатков понадобится достаточное количество дискового пространства. От шага хеша зависит размер такого отпечатка - чем меньше шаг, тем больше отпечаток. Если снимать хеш с шагом в один символ, то размер отпечатка превысит размер самого образца. Если для уменьшения «веса» отпечатка увеличить шаг (например, 10 000 символов), то вместе с этим увеличивается вероятность того, что документ, содержащий цитату из образца длиной в 9 900 символов, будет конфиденциальным, но при этом проскочит незаметно.
С другой стороны, если для увеличения точности детекта брать очень мелкий шаг, несколько символов, то можно увеличить количество ложных срабатываний до неприемлемой величины. В терминах текста это означает, что не стоит снимать хеш с каждой буквы - все слова состоят из букв, и система будет принимать наличие букв в тексте за содержание цитаты из текста-образца. Обычно производители сами рекомендуют некоторый оптимальный шаг снятия хешей, чтобы размер цитаты был достаточный и при этом вес самого отпечатка был небольшой - от 3% (текст) до 15% (сжатое видео). В некоторых продуктах производители позволяют менять размер значимости цитаты, то есть увеличивать или уменьшать шаг хеша.
Достоинства технологии
Как можно понять из описания, для детектирования цитаты нужен объект-образец. И статистические методы могут с хорошей точностью (до 100%) сказать, есть в проверяемом файле значимая цитата из образца или нет. То есть система не берет на себя ответственность за категоризацию документов - такая работа полностью лежит на совести того, кто категоризировал файлы перед снятием отпечатков. Это сильно облегчает защиту информации в случае, если на предприятии в некотором месте (местах) хранятся нечасто изменяющиеся и уже категоризированные файлы. Тогда достаточно с каждого из этих файлов снять отпечаток, и система будет, в соответствии с настройками, блокировать пересылку или копирование файлов, содержащих значимые цитаты из образцов.
Независимость статистических методов от языка текста и нетекстовой информации - тоже неоспоримое преимущество. Они хороши при защите статических цифровых объектов любого типа - картинок, аудио/видео, баз данных. Про защиту динамических объектов я расскажу в разделе «недостатки».
Недостатки технологии
Как и в случае с лингвистикой, недостатки технологии - обратная сторона достоинств. Простота обучения системы (указал системе файл, и он уже защищен) перекладывает на пользователя ответственность за обучение системы. Если вдруг конфиденциальный файл оказался не в том месте либо не был проиндексирован по халатности или злому умыслу, то система его защищать не будет. Соответственно, компании, заботящиеся о защите конфиденциальной информации от утечки, должны предусмотреть процедуру контроля того, как индексируются DLP-системой конфиденциальные файлы.
Еще один недостаток - физический размер отпечатка. Автор неоднократно видел впечатляющие пилотные проекты на отпечатках, когда DLP-система со 100% вероятностью блокирует пересылку документов, содержащих значимые цитаты из трехсот документов-образцов. Однако через год эксплуатации системы в боевом режиме отпечаток каждого исходящего письма сравнивается уже не с тремя сотнями, а с миллионами отпечатков-образцов, что существенно замедляет работу почтовой системы, вызывая задержки в десятки минут.
Как я и обещал выше, опишу свой опыт по защите динамических объектов с помощью статистических методов. Время снятия отпечатка напрямую зависит от размера файла и его формата. Для текстового документа типа этой статьи это занимает доли секунды, для полуторачасового MP4-фильма - десятки секунд. Для редкоизменяемых файлов это не критично, но если объект меняется каждую минуту или даже секунду, то возникает проблема: после каждого изменения объекта с него нужно снять новый отпечаток… Код, над которым работает программист, еще не самая большая сложность, гораздо хуже с базами данных, используемыми в биллинге, АБС или call-центрах. Если время снятия отпечатка больше, чем время неизменности объекта, то задача решения не имеет. Это не такой уж и экзотический случай - например, отпечаток базы данных, хранящей номера телефонов клиентов федерального сотового оператора, снимается несколько дней, а меняется ежесекундно. Поэтому, когда DLP-вендор утверждает, что его продукт может защитить вашу базу данных, мысленно добавляйте слово «квазистатическую».
Единство и борьба противоположностей
Как видно из предыдущего раздела статьи, сила одной технологии проявляется там, где слаба другая. Лингвистике не нужны образцы, она категоризирует данные на лету и может защищать информацию, с которой случайно или умышленно не был снят отпечаток. Отпечаток дает лучшую точность и поэтому предпочтительнее для использования в автоматическом режиме. Лингвистика отлично работает с текстами, отпечатки - с другими форматами хранения информации.
Поэтому большинство компаний-лидеров используют в своих разработках обе технологии, при этом одна из них является основной, а другая - дополнительной. Это связано с тем, что изначально продукты компании использовали только одну технологию, в которой компания продвинулась дальше, а затем, по требованию рынка, была подключена вторая. Так, например, ранее InfoWatch использовал только лицензированную лингвистическую технологию Morph-OLogic, а Websense - технологию PreciseID, относящуюся к категории Digital Fingerprint, но сейчас компании используют оба метода. В идеале использовать две эти технологии нужно не параллельно, а последовательно. Например, отпечатки лучше справятся с определением типа документа - договор это или балансовая ведомость, например. Затем можно подключать уже лингвистическую базу, созданную специально для этой категории. Это сильно экономит вычислительные ресурсы.
За пределами статьи остались еще несколько типов технологий, используемых в DLP-продуктах. К таким относятся, например, анализатор структур, позволяющий находить в объектах формальные структуры (номера кредитных карт, паспортов, ИНН и так далее), которые невозможно детектировать ни с помощью лингвистики, ни с помощью отпечатков. Также не раскрыта тема разного типа меток - от записей в атрибутных полях файла или просто специального наименования файлов до специальных криптоконтейнеров. Последняя технология отживает свое, поскольку большинство производителей предпочитает не изобретать велосипед самостоятельно, а интегрироваться с производителями DRM-систем, такими как Oracle IRM или Microsoft RMS.
DLP-продукты - быстроразвивающаяся отрасль информационной безопасности, у некоторых производителей новые версии выходят очень часто, более одного раза в год. С нетерпением ждем появления новых технологий анализа корпоративного информационного поля для увеличения эффективности защиты конфиденциальной информации.
В наши дни можно часто услышать о такой технологии, как DLP-системы. Что это такое, и где это используется? Это программное обеспечение, предназначенное для предотвращения потери данных путем обнаружения возможных нарушений при их отправке и фильтрации. Кроме того, такие сервисы осуществляют мониторинг, обнаружение и блокирование при ее использовании, движении (сетевом трафике), а также хранении.
Как правило, утечка конфиденциальных данных происходит по причине работы с техникой неопытных пользователей либо является результатом злонамеренных действий. Такая информация в виде частных или корпоративных сведений, объектов интеллектуальной собственности (ИС), финансовой или медицинской информации, сведений кредитных карт и тому подобное нуждается в усиленных мерах защиты, которые могут предложить современные информационные технологии.
Термины «потеря данных» и «утечка данных» связаны между собой и часто используются как синонимы, хотя они несколько отличаются. Случаи утери информации превращаются в ее утечку тогда, когда источник, содержащий конфиденциальные сведения, пропадает и впоследствии оказывается у несанкционированной стороны. Тем не менее утечка данных возможна без их потери.
Категории DLP
Технологические средства, используемые для борьбы с утечкой данных, можно разделить на следующие категории: стандартные меры безопасности, интеллектуальные (продвинутые) меры, контроль доступа и шифрование, а также специализированные DLP-системы (что это такое - подробно описано ниже).

Стандартные меры
Такие стандартные меры безопасности, как системы обнаружения вторжений (IDS) и антивирусное программное обеспечение, представляют собой обычные доступные механизмы, которые охраняют компьютеры от аутсайдера, а также инсайдерских атак. Подключение брандмауэра, к примеру, исключает доступ к внутренней сети посторонних лиц, а система обнаружения вторжений обнаруживает попытки проникновения. Внутренние атаки возможно предотвратить путем проверки антивирусом, обнаруживающих установленных на ПК, которые отправляют конфиденциальную информацию, а также за счет использования сервисов, которые работают в архитектуре клиент-сервер без каких-либо личных или конфиденциальных данных, хранящихся на компьютере.
Дополнительные меры безопасности
Дополнительные меры безопасности используют узкоспециализированные сервисы и временные алгоритмы для обнаружения ненормального доступа к данным (т. е. к базам данных либо информационно-поисковых системам) или ненормального обмена электронной почтой. Кроме того, такие современные информационные технологии выявляют программы и запросы, поступающие с вредоносными намерениями, и осуществляют глубокие проверки компьютерных систем (например, распознавание нажатий клавиш или звуков динамика). Некоторые такие сервисы способны даже проводить мониторинг активности пользователей для обнаружения необычного доступа к данным.

Специально разработанные DLP-системы - что это такое?
Разработанные для защиты информации DLP-решения служат для обнаружения и предотвращения несанкционированных попыток копировать или передавать конфиденциальные данные (преднамеренно или непреднамеренно) без разрешения или доступа, как правило, со стороны пользователей, которые имеют право доступа к конфиденциальным данным.
Для того чтобы классифицировать определенную информацию и регулировать доступ к ней, эти системы используют такие механизмы, как точное соответствие данных, структурированная дактилоскопия, прием правил и регулярных выражений, опубликований кодовых фраз, концептуальных определений и ключевых слов. Типы и сравнение DLP-систем можно представить следующим образом.
Network DLP (также известная как анализ данных в движении или DiM)
Как правило, она представляет собой аппаратное решение либо программное обеспечение, которое устанавливается в точках сети, исходящих вблизи периметра. Она анализирует сетевой трафик для обнаружения конфиденциальных данных, отправляемых в нарушение

Endpoint DLP (данные при использовании )
Такие системы функционируют на рабочих станциях конечных пользователей или серверов в различных организациях.
Как и в других сетевых системах, конечная точка может быть обращена как к внутренним, так и к внешним связям и, следовательно, может быть использована для контроля потока информации между типами либо группами пользователей (например, «файерволы»). Они также способны осуществлять контроль за электронной почтой и обменом мгновенными сообщениями. Это происходит следующим образом - прежде, чем сообщения будут загружены на устройство, они проверяются сервисом, и при содержании в них неблагоприятного запроса они блокируются. В результате они становятся неоправленными и не подпадают под действие правил хранения данных на устройстве.
DLP-система (технология) имеет преимущество в том, что она может контролировать и управлять доступом к устройствам физического типа (к примеру, мобильные устройства с возможностями хранения данных), а также иногда получать доступ к информации до ее шифрования.

Некоторые системы, функционирующие на основе конечных точек, также могут обеспечить контроль приложений, чтобы блокировать попытки передачи конфиденциальной информации, а также обеспечить незамедлительную обратную связь с пользователем. Вместе с тем они имеют недостаток в том, что они должны быть установлены на каждой рабочей станции в сети, и не могут быть использованы на мобильных устройствах (например, на сотовых телефонах и КПК) или там, где они не могут быть практически установлены (например, на рабочей станции в интернет-кафе). Это обстоятельство необходимо учитывать, делая выбор DLP-системы для каких-либо целей.
Идентификация данных
DLP-системы включают в себя несколько методов, направленных на выявление секретной либо конфиденциальной информации. Иногда этот процесс путают с расшифровкой. Однако идентификация данных представляет собой процесс, посредством которого организации используют технологию DLP, чтобы определить, что искать (в движении, в состоянии покоя или в использовании).
Данные при этом классифицируются как структурированные или неструктурированные. Первый тип хранится в фиксированных полях внутри файла (например, в виде электронных таблиц), в то время как неструктурированный относится к свободной форме текста (в форме текстовых документов или PDF-файлов).
По оценкам специалистов, 80% всех данных - неструктурированные. Соответственно, 20% - структурированные. основывается на контент-анализе, ориентированном на структурированную информацию и контекстный анализ. Он делается по месту создания приложения или системы, в которой возникли данные. Таким образом, ответом на вопрос «DLP-системы - что это такое?» послужит определение алгоритма анализа информации.
Используемые методы
Методы описания конфиденциального содержимого на сегодняшний день многочисленны. Их можно разделить на две категории: точные и неточные.
Точные методы - это те, которые связаны с анализом контента и практически сводят к нулю ложные положительные ответы на запросы.
Все остальные являются неточными и могут включать в себя: словари, ключевые слова, регулярные выражения, расширенные регулярные выражения, мета-теги данных, байесовский анализ, статистический анализ и т. д.

Эффективность анализа напрямую зависит от его точности. DLP-система, рейтинг которой высок, имеет высокие показатели по данному параметру. Точность идентификации DLP имеет важное значение для избегания ложных срабатываний и негативных последствий. Точность может зависеть от многих факторов, некоторые из которых могут быть ситуативными или технологическими. Тестирование точности может обеспечить надежность работы DLP-системы - практически нулевое количество ложных срабатываний.
Обнаружение и предотвращение утечек информации
Иногда источник распределения данных делает конфиденциальную информацию доступной для третьих лиц. Через некоторое время часть ее, вероятнее всего, обнаружится в несанкционированном месте (например, в интернете или на ноутбуке другого пользователя). DLP-системы, цена которых предоставляется разработчиками по запросу и может составлять от нескольких десятков до нескольких тысяч рублей, должны затем исследовать, как просочились данные - от одного или нескольких третьих лиц, было ли это независимо друг от друга, не обеспечивалась ли утечка какими-то другими средствами и т. д.
Данные в покое
«Данные в состоянии покоя» относятся к старой архивной информации, хранящейся на любом из жестких дисков клиентского ПК, на удаленном файловом сервере, на диске Также это определение относится к данным, хранящимся в системе резервного копирования (на флешках или компакт-дисках). Эти сведения представляют большой интерес для предприятий и государственных учреждений просто потому, что большой объем данных содержится неиспользованным в устройствах памяти, и более вероятно, что доступ к ним может быть получен неуполномоченными лицами за пределами сети.
Технология DLP (Data Loss Prevention ) - технологии предотвращения утечек конфиденциальной информации из информационной системы вовне, а также технические устройства (программные или программно-аппаратные) для такого предотвращения утечек. Конкурентным преимуществом большинства систем является модуль анализа. Производители настолько выпячивают этот модуль, что часто называют по нему свои продукты, например «DLP-решение на базе меток». Поэтому пользователь выбирает решения зачастую не по производительности, масштабируемости или другим, традиционным для корпоративного рынка информационной безопасности критериям, а именно на основе используемого типа анализа документов. Очевидно, что, поскольку каждый метод имеет свои достоинства и недостатки, использование только одного метода анализа документов ставит решение в технологическую зависимость от него. Большинство производителей используют несколько методов, хотя один из них обычно является «флагманским».
Под DLP многие клиенты и производители решений иногда понимают то, что DLP не является – скажем, систему защиты и блокировки портов. Есть устойчивое мнение, что DLP – это только софт, что тоже в корне неверно. DLP – это целый комплекс организационных и технических мер. Не случайно наиболее дальновидные производители DLP стремятся выйти за рамки систем защиты от утечек в смежные области, нарастить функционал. DLP-проект – дело сложное, это очень много консалтинга, совместной работы с заказчиком, и совсем чуть-чуть собственно внедрения, адаптации системы под инфраструктуру конкретной компании.
Постепенно сложилась концепция трех стадий взаимодействия с клиентом в DLP-проекте: pre-DLP, DLP и post-DLP. На первом этапе команда вендора, интегратора и заказчика совместно разбираются с объектами защиты, выясняют, какую именно конфиденциальную информацию будет отслеживаться в компании. Это во многом консалтинговая работа. На рынке присутствуют автоматические инструменты для помощи компании в категоризации информации. Он позволяет в полуавтоматическом режиме разнести информацию по категориям. В дальнейшем, при анализе исходящего трафика, система определяет, к какой категории или категориям относится исходящий документ, сопоставляет его с уже имеющимися образцами (сравниваются векторы документов, построенные в многомерном пространстве. Измерения этого пространства - термины). Если вектор документа близок к вектору эталонного конфиденциального документа, система сообщает об этом или блокирует отправку (в зависимости от настроек). Это сложная гибридная лингвистика в действии. На этапе pre-DLP важно подготовить такую классификацию, чтобы у системы в процессе работы не возникало ни сомнений, ни ложных срабатываний.
Внедрение – это простая часть, обычно она занимает от одного до нескольких дней. По сути это просто развертывание софта на всю компанию. Если там сложная, большая разветвленная инфраструктура, это будет подольше. Стадия post-DLP предполагает работу с системой, когда инцидент уже произошел. При соблюдении в компании ряда процедур данные системы могут использоваться в качестве доказательства в суде (в случае преследования нарушителя за несоблюдение режима коммерческой тайны, например).
По подсчетам ABI Research, к концу 2014 года рынок решений Data Loss Prevention достигнет $1,7 млрд. Аналитики компании Gartner придерживаются оценки в $830 млн. По словам Натальи Касперской, генерального директора InfoWatch, российский рынок DLP-систем в 2014 году вырос на 30-35%, а весь мировой рынок составил $700 млн.
В России работает несколько компаний - производителей DLP-систем (основные - InfoWatch, «Инфосистемы Джет», Zecurion, SearchInform). По прогнозам Anti-Malware, сделанном в сентябре 2014 года, по итогам 2014 года объем российского рынка DLP-систем составит $85 – 88 млн. По внедрениям DLP-систем в России лидируют крупный бизнес (64%), госсектор (26%) и средний бизнес (10%).
1 июня 2014 г. вступил в действие новый стандарт обеспечения информационной безопасности в банках, рекомендованный им Банком России. Согласно стандарту, Банк России рекомендует российским банкам внедрять системы Data Loss Prevention (DLP), чтобы предотвратить утечку данных о клиентах. С их помощью кредитные организации смогут анализировать переписку сотрудников, а также выяснять, какими интернет-сайтами они пользуются.
Вступивший в силу 1 июня новый стандарт заменил старый, действовавший с 2010 года. В документе впервые говорится об «утечке данных» и прописаны меры для ее предотвращения. Для этого Центробанк России разрешил банкам использовать DLP (Data Loss Prevention - система для предотвращения утечек). Этот тип программного обеспечения устанавливается на компьютеры сотрудников и корпоративные серверы и позволяет отслеживать все их действия в интернете, а также переписку и обмен информацией.
Применение DLP обязывает банки архивировать электронную почту, чтобы в случае утечки информации можно было отследить ее источник. Кроме того, стандарт безопасности подразумевает применение защищенных сетевых протоколов.
Кроме того, согласно тексту внесенного в Думу документа, компании планируется наделить возможностью получать дистанционное согласие гражданина на обработку его персональных данных. В настоящее время сделать это можно только при личном присутствии человека.