Особенности работы HTTP протокола. Протокол HTTP
Здравствуйте, уважаемые читатели блога сайт. При изучении механизма, отвечающего за корректное функционирование сети интернет, никуда не уйти от необходимости уделить время его основным аспектам, в число коих, вне всякого сомнения, входит протокол передачи данных HTTP и его безопасная версия HTTPS.
Основой работы этого инструмента, позволяющего браузеру пользователя открывать нужные файлы и документы для получения информации, является технология «клиент-сервер», подробности которой рассмотрим в этой статье чуть ниже.
Конечно, тем, кто желает по-настоящему посвятить свою деятельность работе с компьютерными сетями и разработке сетевых программ, необходимо изучить этот вопрос по максимуму для получения соответствующей квалификации. Но нам это не требуется.
Главное — понять, что представляет из себя HTTP в общих чертах и каковы главные особенности HTTPS, а также постичь базовые принципы, которые в них заложены. Подобные знания будут полезны в том числе для для оптимизации и продвижения вашего сайта, этому вы получите безусловное подтверждение из этой и последующих статей, посвященных данной теме.
Что такое HTTP и как он работает?
Чтобы получить нужный документ в интернете, пользователю достаточно ввести в поисковую строку браузера нужный URL-адрес ( о структуре урлов подробности), который как раз содержит название протокола HTTP (или HTTPS).
3. HTTP/Версия — указывается действующая модификация протокола. На данный момент это HTTP 1.1 (вы можете ознакомиться с ее спецификацией). Однако, в черновом виде уже существует следующая версия протокола 2.0, который основан на .
Нижняя строка представляет собой заголовок Host в составе HTTP-запроса, отсылаемого браузером серверу в соответствии с полученным от ДНС IP. Для чего это надо? Для идентификации нужного сайта, поскольку на вебсерверах обычно расположен не один ресурс.
Разберем наглядный пример для закрепления пройденного. Скажем, браузер получил "задание" от пользователя отобразить страничку вот с таким адресом:
Http://subscribe.ru/group/
Тогда HTTP-запрос посредством метода GET может быть составлен следующим образом (в этом случае обычно тело сообщения отсутствует):
GET /group/ HTTP/1.1 Host: subscribe.ru
Для наглядности я предоставил лишь самый простой пример, включающий один заголовок Host, на самом деле, их может быть несколько. Но это не все. Ведь для полноценного общения необходим диалог, который и устанавливается после того, как на запрос браузера сервер дает ответ. Начальную строку ответа тоже можно изобразить схематически:
HTTP/Версия Код состояния Пояснение
Теперь пробежимся вкратце и по составу ответа сервера:
1. Версия HTTP указывается по аналогии с запросом.
2. Код состояния (Status Code) — три цифры, информирующие о том, каков статус документа, запрошенного браузером. Например, 200 — ОК, страница существует и будет отображена в браузере, 301 — осуществлен (перенаправление) на другой урл, — вебстранички по такому адресу нет (возможно, она удалена либо юзер ошибся при вводе URL).
3. Пояснение (Reason Phrase) — текст дополнения к коду ответа. В некоторых случаях пояснение может отличаться от стандартного либо отсутствовать вовсе. Это связано в том числе с настройкой ПО, размещенного на сервере.
Реальный пример? Пожалуйста. Попробуем получить ответ сервера на запрос, приведенный мною в качестве примера выше (урл «http://subscribe.ru/group/»). Он будет выглядеть так (начальная строка с заголовками):
HTTP/1.1 200 OK Server: nginx Date: Sat, 10 Jun 2017 06:36:38 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Content-Language: ru Set-Cookie: Subscribe::Viziter=UQkivlk7k3YO3DgjAxM2Ag==; expires=Thu, 31-Dec-37 23:55:55 GMT; domain=subscribe.ru; path=/ P3P: policyref="/w3c/p3p.xml", CP="NOI PSA OUR BUS UNI"
В данном случае отсутствуют пояснение и тело сообщения, которое при использовании метода GET может содержать, например, HTML-код запрашиваемого документа (веб-странички). В зависимости от типа приложения клиента эти разделы могут присутствовать.
Итак, резюмируем вкратце выше изложенное. Если пользователь вводит урл искомой страницы, имея ввиду получить ее содержимое для просмотра, браузер посылает GET запрос на нужный сервер и получает ответ. В результате этого общения либо (при благоприятных обстоятельствах) контент запрошенного документа будет отображен, либо нет.
В любом случае, по содержанию HTTP-ответа сервера (включая код состояния) можно получить полезную информацию, связанную с запрашиваемым документом.
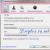
Для того, чтобы выше предложенная информация без усилий ложилась в пазл, не хватает конкретного примера. Его мы рассмотрим с помощью одного из (именно этот веб-обозреватель является моим рабочим инструментом), именуемого HTTP Headers.
Он удобен тем, что дает полную картину взаимодействия «клиент-сервер», предоставляя в "одном флаконе" содержание HTTP запроса (request) и ответа (response) . Посмотрите, какой документ выдал этот плагин при переходе по ссылке с одной страницы моего блога на другую:

Здесь в самом верху отмечен метод GET, с помощью которого браузер обращается к серверу, а также статус странички, отмеченный кодом состояния 200 OK, который дает понять, что сервер передал все данные в отношении запрашиваемой вебстраницы.
Интерес вызывают также HTTP Headers (заголовки) , отображенные ниже. Например, пункт «Referer» дает информацию в виде урла, откуда был осуществлен переход.
Заголовок «User Agent» отражает как раз клиентское приложение, отправившее запрос вебсерверу. В данном случае это браузер, но могут быть и другие (мобильные устройства, поисковые роботы и т.д.). Данные, представленные в Юзер Агенте, необходимы серверному программному обеспечению для идентификации приложения, посылающего запрос.
Как раз боты поисковых систем , сканирующие страницы сайтов для получения информации, влияющей на ранжирование, нас и интересуют в первую очередь, потому как именно они решают судьбу той или иной страницы в плане эффективности ее продвижения.
Вот потому-то в следующей публикации я планирую поподробнее остановится на том, как просмотреть HTTP-заголовки и проверить коды ответов сервера именно на запрос робота, что исключительно важно для вебмастеров в свете SEO оптимизации ресурса. Поэтому оформляйте подписку , чтобы своевременно получить свежую статью.
В чем особенность безопасного протокола HTTPS?
Уверен, всем без исключения пользователям интернета, включая начинающих, известно о существовании особого протокола HTTPS (Hypertext Transfer Protocol Secure), который служит для защиты персональных данных на сервисах, где используется их передача (платежные системы, интернет магазины, крупные специализированные порталы и т.д.).
Если ввести адрес страницы какого-нибудь подобного сайта, то данное соединение будет особым образом обозначено. В Google Chrome (), например, отобразится замочек с надписью «Надёжный» зеленого цвета, при нажатии на который вы увидите некоторую информацию, связанную с защитой личных данных:

Что такое HTTPS? Строго говоря, он не является самостоятельным протоколом. Это стандартный HTTP, который действует через механизмы TLS или SSL , способные гарантировать шифрование, что исключает перехват и получение конфиденциальных данных злоумышленниками.
По умолчанию при работе защищенного протокола применяется порт 443 (если помните, для стандартного HTTP — 80). Для шифрования в HTTPS используется длина ключа в 40, 56, 128 и 256 бит (). Однако, первые два варианта даже не стоит рассматривать, поскольку они не могут обеспечить достаточного уровня безопасности.
В последнее время поисковики, особенно Гугл, активно склоняют владельцев всех сайтов к переходу на защищенный протокол, тонко намекая, что этот момент будет учитываться при ранжировании. В итоге теперь многие ресурсы (даже обычные блоги), а не только сайты, тесно связанные с передачей личных данных, уже работают с HTTPS.
Более того, передовые хостеры предлагают по приобретению безопасного сертификата SSL, который необходим для включения защищенного соединения.
Конечно, мы не рассмотрели все нюансы использования протокола HTTP (HTTPS), коих немало. Эта тема может занять несколько внушительных мануалов. Однако основные аспекты, которые пригодятся как продвинутому пользователю, так и вебмастеру, освещены. Если вы все-таки не удовлетворены объемом полученной информации, то можете с легкостью дополнить ее из ниже следующей видеолекции, где, в частности, подробнее говорится о методах:
22.04.05 13625
Назначение протокола
HyperText Transfer Protocol (HTTP) — это протокол высокого уровня (а именно, уровня приложений), обеспечивающий необходимую скорость передачи данных, требующуюся для распределенных информационных систем гипермедиа. HTTP используется проектом World Wide Web с 1990 года.
Практические информационные системы требуют большего, чем примитивный поиск, модификация и аннотация данных. HTTP/1.0 предоставляет открытое множество методов, которые могут быть использованы для указания целей запроса. Они построены на дисциплине ссылок, где для указания ресурса, к которому должен быть применен данный метод, используется Универсальный Идентификатор Ресурсов (Universal Resource Identifier — URI), в виде местонахождения (URL) или имени (URN). Формат сообщений сходен с форматом Internet Mail или Multipurpose Internet Mail Extensions (MIME-Многоцелевое Расширение Почты Internet).
HTTP/1.0 используется также для коммуникаций между различными пользовательскими просмотрщиками и шлюзами, дающими гипермедиа доступ к существующим Internet протоколам, таким как SMTP, NNTP, FTP, Gopher и WAIS. HTTP/1.0 разработан, чтобы позволять таким шлюзам через proxy серверы, без какой-либо потери передавать данные с помощью упомянутых протоколов более ранних версий.
Общая Структура
HTTP основывается на парадигме запросов/ответов. Запрашивающая программа (обычно она называется клиент) устанавливает связь с обслуживающей программой-получателем (обычно называется сервер) и посылает запрос серверу в следующей форме: метод запроса, URI, версия протокола, за которой следует MIME-подобное сообщение, содержащее управляющую информацию запроса, информацию о клиенте и, может быть, тело сообщения. Сервер отвечает сообщением, содержащим строку статуса (включая версию протокола и код статуса — успех или ошибка), за которой следует MIME-подобное сообщение, включающее в себя информацию о сервере, метаинформацию о содержании ответа, и, вероятно, само тело ответа. Следует отметить, что одна программа может быть одновременно и клиентом и сервером. Использование этих терминов в данном тексте относится только к роли, выполняемой программой в течение данного конкретного сеанса связи, а не к общим функциям программы.
В Internet коммуникации обычно основываются на TCP/IP протоколах. Для WWW номер порта по умолчанию — TCP 80, но также могут быть использованы и другие номера портов — это не исключает возможности использовать HTTP в качестве протокола верхнего уровня.
Для большинства приложений сеанс связи открывается клиентом для каждого запроса и закрывается сервером после окончания ответа на запрос. Тем не менее, это не является особенностью протокола. И клиент, и сервер должны иметь возможность закрывать сеанс связи, например, в результате какого-нибудь действия пользователя. В любом случае, разрыв связи, инициированный любой стороной, прерывает текущий запрос, независимо от его статуса.
Общие понятия
Запрос
— это сообщение, посылаемое клиентом серверу.
Первая строка этого сообщения включает в себя метод, который должен быть применен к запрашиваемому ресурсу, идентификатор ресурса и используемую версию протокола. Для совместимости с протоколом HTTP/0.9, существует два формата HTTP запроса:
Запрос = Простой-Запрос | Полный-Запрос Простой-Запрос = "GET" SP Запрашиваемый-URI CRLF Полный-Запрос = Строка-Статус *(Общий-Заголовок | Заголовок-Запроса | Заголовок-Содержания) CRLF [ Содержание-Запроса ]
Если HTTP/1.0 сервер получает Простой-Запрос, он должен отвечать Простым-Ответом HTTP/0.9. HTTP/1.0 клиент, способный обрабатывать Полный-Ответ, никогда не должен посылать Простой-Запрос.
Строка Статус
Строка Статус начинается со строки с названием метода, за которым следует URI-Запроса и использующаяся версия протокола. Строка Статус заканчивается символами CRLF. Элементы строки разделяются пробелами (SP). В Строке Статус не допускаются символы LF и CR, за исключением заключающей последовательности CRLF.
Строка-Статус = Метод SP URI-Запроса SP Версия-HTTP CRLF
Следует отметить, что отличие Строки Статус Полного-Запроса от Строки Статус Простого- Запроса заключается в присутствии поля Версия-HTTP.
Метод
В поле Метод указывается метод, который должен быть применен к ресурсу, идентифицируемому URI-Запроса. Названия методов чувствительны к регистру. Существующий список методов может быть расширен.
Метод = "GET" | "HEAD" | "PUT" | "POST" | "DELETE" | "LINK" | "UNLINK" | дополнительный-метод
Список методов, допускаемых отдельным ресурсом, может быть указан в поле Заголовок-Содержание «Баллов». Тем не менее, клиент всегда оповещается сервером через код статуса ответа, допускается ли применение данного метода для указанного ресурса, так как допустимость применения различных методов может динамически изменяться. Если данный метод известен серверу, но не допускается для указанного ресурса, сервер должен вернуть код статуса «405 Method Not Allowed», и код статуса «501 Not Implemented», если метод не известен или не поддерживается данным сервером. Общие методы HTTP/1.0 описываются ниже.
GET
Метод GET служит для получения любой информации, идентифицированной URI-Запроса. Если URI- Запроса ссылается на процесс, выдающий данные, в качестве ответа будут выступать данные, сгенерированные данным процессом, а не код самого процесса (если только это не является выходными данными процесса).
Метод GET изменяется на «условный GET», если сообщение запроса включает в себя поле заголовка «If-Modified-Since». В ответ на условный GET, тело запрашиваемого ресурса передается только, если он изменялся после даты, указанной в заголовке «If-Modified-Since». Алгоритм определения этого включает в себя следующие случаи:
- Если код статуса ответа на запрос будет отличаться от «200 OK», или дата, указанная в поле заголовка «If-Modified-Since» некорректна, ответ будет идентичен ответу на обычный запрос GET.
- Если после указанной даты ресурс изменялся, ответ будет также идентичен ответу на обычный запрос GET.
- Если ресурс не изменялся после указанной даты, сервер вернет код статуса «304 Not Modified».
Использование метода условный GET направлено на разгрузку сети, так как он позволяет не передавать по сети избыточную информацию.
HEAD
Метод HEAD аналогичен методу GET, за исключением того, что в ответе сервер не возвращает Тело- Ответа. Метаинформация, содержащаяся в HTTP заголовках ответа на запрос HEAD, должна быть идентична информации HTTP заголовков ответа на запрос GET. Данный метод может использоваться для получения метаинформации о ресурсе без передачи по сети самого ресурса. Метод «Условный HEAD», аналогичный условному GET, не определен.
POST
Метод POST используется для запроса сервера, чтобы тот принял информацию, включенную в запрос, как субординантную для ресурса, указанного в Строке Статус в поле URI-Запроса. Метод POST был разработан, чтобы была возможность использовать один общий метод для следующих функций:
- Аннотация существующих ресурсов
- Добавление сообщений в группы новостей, почтовые списки или подобные группы статей
- Доставка блоков данных процессам, обрабатывающим данные
- Расширение баз данных через операцию добавления
Реальная функция, выполняемая методом POST, определяется сервером и обычно зависит от URI- Запроса. Добавляемая информация рассматривается как субординатная указанному URI в том же смысле, как файл субординатен каталогу, в котором он находится, новая статья субординатна группе новостей, в которую она добавляется, запись субординатна базе данных.
Клиент может предложить URI для идентификации нового ресурса, включив в запрос заголовок «URI». Тем не менее, сервер должен рассматривать этот URI только как совет и может сохранить тело запроса под другим URI или вообще без него.
Если в результате обработки запроса POST был создан новый ресурс, ответ должен иметь код статуса, равный «201 Created», и содержать URI нового ресурса.
PUT
Метод PUT запрашивает сервер о сохранении Тело-Запроса под URI, равным URI-Запроса. Если URI-Запроса ссылается на уже существующий ресурс, Тело-Запроса должно рассматриваться как модифицированная версия данного ресурса. Если ресурс, на который ссылается URI-Запроса не существует, и данный URI может рассматриваться как описание для нового ресурса, сервер может создать ресурс с данным URI. Если был создан новый ресурс, сервер должен информировать направившего запрос клиента через ответ с кодом статуса «201 Created». Если существующий ресурс был модифицирован, должен быть послан ответ «200 OK», для информирования клиента об успешном завершении операции. Если ресурс с указанным URI не может быть создан или модифицирован, должно быть послано соответствующее сообщение об ошибке.
Фундаментальное различие между методами POST и PUT заключается в различном значении поля URI-Запроса. Для метода POST данный URI указывает ресурс, который будет управлять информацией, содержащейся в теле запроса, как неким придатком. Ресурс может быть обрабатывающим данные процессом, шлюзом в какой нибудь другой протокол, или отдельным ресурсом, допускающим аннотации. В противоположность этому, URI для запроса PUT идентифицирует информацию, содержащуюся в Содержание-Запроса. Использующий запрос PUT точно знает какой URI он собирается использовать, и получатель запроса не должен пытаться применить этот запрос к какому-нибудь другому ресурсу.
DELETE
Метод DELETE используется для удаления ресурсов, идентифицированных с помощью URI-Запроса. Результаты работы данного метода на сервере могут быть изменены с помощью человеческого вмешательства (или каким-нибудь другим способом). В принципе, клиент никогда не может быть уверен, что операция удаления была выполнена, даже если код статуса, переданный сервером, информирует об успешном выполнении действия. Тем не менее, сервер не должен информировать об успехе до тех пор, пока на момент ответа он не будет собираться стереть данный ресурс или переместить его в некоторую недостижимую область.
LINK
Метод LINK устанавливает взаимосвязи между существующим ресурсом, указанным в URI-Запроса, и другими существующими ресурсами. Отличие метода LINK от остальных методов, допускающих установление ссылок между документами, заключается в том, что метод LINK не позволяет передавать в запросе Тело-Запроса, и в том, что в результате работы данного метода не создаются новые ресурсы.
UNLINK
Метод UNLINK удаляет одну или более ссылочных взаимосвязей для ресурса, указанного в URI- Запроса. Эти взаимосвязи могут быть установлены с помощью метода LINK или какого-нибудь другого метода, поддерживающего заголовок «Link». Удаление ссылки на ресурс не означает, что ресурс прекращает существование или становится недоступным для будущих ссылок.
Поля Заголовок-Запроса
Поля Заголовок-Запроса позволяют клиенту передавать серверу дополнительную информацию о запросе и о самом клиенте.
Заголовок-Запроса = Accept | Accept-Charset | Accept-Encoding | Accept-Language | Authorization | From | If-Modified-Since | Pragma | Referer | User-Agent | extension-header
Кроме того через механизм расширения могут быть определены дополнительные заголовки; приложения, которые их не распознают, должны трактовать эти заголовки, как Заголовок-Содержание.
Ниже будут рассмотрены некоторые поля заголовка запроса.
From
В случае присутствия поля From, оно должно содержать полный E-mail адрес пользователя, который управляет программой-агентом, осуществляющей запросы. Этот адрес должен быть задан в формате, определенном в RFC 822. Формат данного поля следующий: From = «From» «:» спецификация адреса. Например:
From: [email protected]
Данное поле может быть использовано для функций захода в систему, а также для идентификации источника некорректных или нежелательных запросов. Оно не должно использоваться, как несекретная форма разграничения прав доступа. Интерпретация этого поля состоит в том, что обрабатываемый запрос производится от имени данного пользователя, который принимает ответственность за применяемый метод. В частности, агенты-роботы должны использовать этот заголовок для того, чтобы можно было связаться с тем человеком, который отвечает за работу робота, в случае возникновения проблем. Почтовый Internet адрес, указывающийся в этом поле, не обязан соответствовать адресу того хоста, с которого был послан данный запрос. По возможности, адрес должен быть доступным Internet адресом вне зависимости от того, является ли он в действительности Internet E-mail адресом или Internet E-mail представлением адреса других почтовых систем.
Замечание: Клиент не должен использовать поле заголовка From без позволения пользователя, так как это может войти в конфликт с его частными интересами или с местной, используемой им, системой безопасности. Настоятельно рекомендуется предоставление пользователю возможности запретить, разрешить или модифицировать это поле в любой момент перед запросом.
If-Modified-Since
Поле заголовка If-Modified-Since используется с методом GET для того, чтобы сделать его условным: если запрашиваемый ресурс не изменялся во времени, указанного в этом поле, копия этого ресурса не будет возвращена сервером; вместо этого, будет возвращен ответ «304 Not Modified» без Тела- Ответа.
If-Modified-Since = "If-Modified-Since" ":" HTTP-дата
Пример использования заголовка:
Целью этой особенности является предоставление возможности эффективного обновления информации локальных кэшей с минимумом передаваемой информации. Тот же результат может быть достигнут применением метода HEAD с последующим использованием GET, если сервер указал, что содержимое документа изменилось.
User-Agent
Поле заголовка User-Agent содержит информацию о пользовательском агенте, пославшем запрос. Данное поле используется для статистики, прослеживания ошибок протокола, и автоматического распознавания пользовательских агентов. Хотя это не обязательно, пользовательские агенты должны всегда включать это поле в свои запросы. Поле может содержать несколько строк, представляющих собой название программного продукта, необязательную косую черту с указанием версии продукта, а также другие программные продукты, составляющие важную часть пользовательского агента. По соглашению, продукты указываются в списке в порядке убывания их значимости для идентификации приложения.
User-Agent = "User-Agent" ":" 1*(продукт) продукт = строка ["/" версия-продукта] версия-продукта = строка
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Строка, описывающая название продукта, должна быть короткой и давать информацию по существу — использование данного заголовка для рекламирования какой-либо другой, не относящейся к делу, информации не допускается и рассматривается, как не соответствующее протоколу. Хотя в поле версии продукта может присутствовать любая строка, данная строка должна использоваться только для указания версии продукта. Поле User-Agent может включать в себя дополнительную информацию в комментариях, которые не являются частью его значения.
Структура ответа
После получения и интерпретации запроса, сервер посылает ответ в соответствии со следующей формой:
Ответ = Простой-Ответ | Полный-Ответ Простой-Ответ = [ Содержание-Ответа ] Полный-Ответ = Строка-Статус *(Общий-Заголовок | Заголовок-Ответа | Заголовок-Содержания) CRLF [ Содержание-Ответа ]
Простой-Ответ должен посылаться только в ответ на HTTP/0.9 Простой-Запрос, или в том случае, если сервер поддерживает только ограниченный HTTP/0.9 протокол. Если клиент посылает HTTP/1.0 Полный-Запрос и получает ответ, который не начинается со Строки-Статус, он должен предполагать, что ответ сервера представляет собой Простой-Ответ, и обрабатывать его в соответствии с этим. Следует заметить, что Простой-Ответ состоит только из запрашиваемой информации (без заголовков) и поток данных прекращается в тот момент, когда сервер закрывает сеанс связи.
Строка Статус
Первая строка Полного-Запроса является Строкой-Статус, состоящей из версии протокола, за которой следует цифровой код статуса и ассоциированное с ним текстовое предложение. Все элементы Строки-Статус разделены пробелами. Не разрешены символы CR и LF, за исключением завершающей последовательности CRLF.
Строка-Статус=Версия-HTTP SP Статус-Код SP Фраза-Об"яснение.
Так как Строка-Статус всегда начинается с версии протокола «HTTP/» 1*ЦИФРА «.» 1*ЦИФРА (например HTTP/1.0), существование этого выражения рассматривается как основное для определения того, является ли ответ Простым-Ответом, или Полным-Ответом. Хотя формат Простого-Ответа не исключает появления подобной строки (что привело бы к неправильной интерпретации сообщения ответа и принятию его за Полный-Ответ), вероятность такого появления близка к нулю.
Статус-Код и пояснение к нему
Элемент Статус-Код представляет собой 3-х цифровой целый код, идентифицирующий результат попытки интерпретации и удовлетворения запроса. Фраза-Об’яснение, следующая за ним, предназначена для краткого текстового описания Статус-Кода. Статус-Код нацелен на то, чтобы его использовала машина, а Фраза-Об’яснение предназначена для человека. Клиент не обязан исследовать и выводить на экран Фразу-Об’яснение.
Первая цифра Статус-Кода предназначена для определения класса ответа. Последние две цифры не выполняют никакой категоризирующей роли. Существует 5 значений для первой цифры:
- 1xx: Информационный — Не используется, но зарезервирован для использования в будущем
- 2xх: Успех — Запрос был полностью получен, понят, и принят к обработке.
- 3xx: Перенаправление — Клиенту следует предпринять дальнейшие действия для успешного выполнения запроса. Необходимое дополнительное действие иногда может быть выполнено клиентом без взаимодействия с пользователем, но настоятельно рекомендуется, чтобы это имело место только в тех случаях, когда метод, использующийся в запросе безразличен (GET или HEAD).
- 4xx: Ошибка клиента — Запрос, содержащий неправильные синтаксические конструкции, не может быть успешно выполнен. Класс 4xx предназначен для описания тех случаев, когда ошибка была допущена со стороны клиента. Если клиент еще не завершил запрос, когда он получил ответ с Статус-Кодом- 4xx, он должен немедленно прекратить передачу данных серверу. Данный тип Статус-Кодов применим для любых методов, употребляющихся в запросе.
- 5xx: Ошибка Сервера — Сервер не смог дать ответ на корректно поставленный запрос. В этих случаях
сервер либо знает, что он допустил ошибку, либо не способен обработать запрос. За исключением ответов на запросы HEAD, сервер посылает описание ошибочной ситуации и то, является ли это состояние временным или постоянным, в Содержание-Ответа. Данный тип Статус-Кодов применим для любых методов, употребляющихся в запросе.
Отдельные значения Статус-Кодов и соответствующие им Фразы-Об’яснения приведены ниже. Данные Фразы-Об’яснения только рекомендуются — они могут быть замещены любыми другими фразами, сохраняющими смысл и допускающимися протоколом.
Статус-Код = "200" ; OK | "201" ; Created | "202" ; Accepted | "203" ; Provisional Information | "204" ; No Content | "300" ; Multiple Choices | "301" ; Moved Permanently | "302" ; Moved Temporarily | "303" ; Method | "304" ; Not Modified | "400" ; Bad Request | "401" ; Unauthorized | "402" ; Payment Required | "403" ; Forbidden | "404" ; Not Found | "405" ; Method Not Allowed | "406" ; None Acceptable | "407" ; Proxy Authentication Required | "408" ; Request Timeout | "409" ; Conflict | "410" ; Gone | "500" ; Internal Server Error | "501" ; Not Implemented | "502" ; Bad Gateway | "503" ; Service Unavailable | "504" ; Gateway Timeout | Код-Рассширения Код-Расширения = 3ЦИФРА Фраза-Об"яснение = строка *(SP строка)
От HTTP приложений не требуется понимание всех Статус-Кодов, хотя такое понимание, очевидно, желательно. Тем не менее, от приложений требуется способность распознавания классов Статус-Кодов (идентифицирующихся первой цифрой) и отношение ко всем Статус-Кодам статуса ответа, как если бы они были эквивалентны Статус-Коду x00.
Поля Заголовок-Ответа
Поля заголовка ответа позволяют серверу передать дополнительную информацию об ответе, которая не может быть внесена в Строку-Статус. Эти поля заголовков не предназначены для передачи информации о содержании ответа, передаваемого в ответ на запрос, но там может быть информация собственно о сервере.
Заголовок-Ответа= Public | Retry-After | Server | WWW-Authenticate | extension-header
Хотя дополнительные поля заголовка ответа могут быть реализованы через механизм расширения, приложения, которые не распознают эти поля, должны обрабатывать их как поля Заголовок-Содержание. Полное описание этих полей можно получить в спецификации протокола HTTP в CERN.
Общие Понятия
Полный-Запрос и Полный-Ответ может использоваться для передачи некоторой информации в отдельных запросах и ответах. Этой информацией является Содержание-Запроса или Содержание-Ответа соответственно, а также Заголовок-Содержания.
Поля Заголовок-Содержания
Поля Заголовок-Содержания содержат необязательную метаинформацию о Содержании-Запроса или Содержании-Ответа соответственно. Если тело соответствующего сообщения (запроса или ответа) не присутствует, то Заголовок-Содержания содержит информацию о запрашиваемом ресурсе.
Некоторые из полей заголовка содержания описаны ниже.
Allow
Поле заголовка Allow представляет собой список методов, которые поддерживает ресурс, идентифицированный URI-Запроса. Назначение этого поля — точное информирование получателя о допустимых методах, ассоциированных с ресурсом; это поле должно присутствовать в ответе со статус кодом «405 Method Not Allowed».
Allow = "Allow" ":" 1#метод
Пример использования:
Allow: GET, HEAD, PUT
Конечно, клиент может попробовать использовать другие методы. Однако, рекомендуется следовать тем методам, которые указаны в данном поле. У этого поля нет значения по умолчанию; если оно оставлено неопределенным, множество разрешенных методов определяется сервером в момент каждого запроса.
Content-Length
Поле Content-Length указывает размер тела сообщения, посланного сервером в ответ на запрос или, в случае запроса HEAD, размер тела сообщения, которое было бы послано в ответ на запрос GET.
Content-Length = "Content-Length" ":" 1*ЦИФРА
Например:
Content-Length: 3495
Хотя это не обязательно, но все же приложениям настоятельно рекомендуется использовать это поле для анализа размеров передаваемого сообщения, независимо от типа содержащейся в нем информации. Для поля Content-Length допустимым является любое целочисленное значение больше нуля.
Content-Type
Поле заголовка Content-Type идентифицирует тип информации в теле сообщения, которая посылается получающей стороне или, в случае метода HEAD, тип информации (среды), который был бы послан, если использовался метод GET.
Content-Type = "Content-Type" ":" тип-среды
Типы сред определены отдельно.
Пример:
Content-Type: text/html; charset=ISO-8859-4
Поле Content-Type не имеет значения по умолчанию.
Last-Modified
Поле заголовка содержит дату и время, в которое, по мнению отправляющей стороны, ресурс был последний раз модифицирован. Семантика данного поля определена в терминах, описывающих, как получатель должен его интерпретировать: если получатель имеет копию ресурса, которая старше, чем передаваемая в поле Last-Modified дата, то копия должна считаться устаревшей.
Last-Modified = "Last-Modified" ":" HTTP-дата
Пример использования:
Точное значение этого поля заголовка зависит от реализации отправляющей стороны и сути самого ресурса. Для файлов, это может быть просто его время последней модификации. Для шлюзов к базам данных, это может быть время последнего обновления данных в базе. В любом случае, получатель должен беспокоиться лишь о результате — о том, что находится в данном поле, — и не беспокоиться о том, как результат был получен.
Тело сообщения
Под телом сообщения понимается Содержание-Запроса или Содержание-Ответа соответственно. Тело сообщения, если оно присутствует, посылается в HTTP/1.0 запросе или ответе в формате и кодировке, определяемыми полями Заголовок-Содержания.
Тело-Сообщения = *OCTET (где OCTET это любой 8-битный символ)
Тело сообщения включается в запрос, только если метод запроса подразумевает его наличие. Для спецификации HTTP/1.0 такими методами являются POST и PUT. В общем, на присутствие тела сообщения указывает присутствие таких полей заголовка содержания, как Content-Length и/или Content- Transfer-Encoding, в передаваемом запросе.
Что касается сообщений-ответов, наличие тела сообщения в ответе зависит от метода, который был использован в запросе, и Статус-Кода. Все ответы на запросы HEAD не должны содержать тело сообщения, хотя наличие некоторых полей заголовка сообщения может указывать на возможное присутствие такового. Соответственно, ответы «204 No Content», «304 Not Modified», и «406 None Acceptable» также не должны включать в себя тело сообщения.
Хорошо Плохо
HTTP (HyperText Transfer Protocol - протокол передачи гипертекста) был разработан как основа World Wide Web.
Работа по протоколу HTTP происходит следующим образом: программа-клиент устанавливает TCP-соединение с сервером (стандартный номер порта-80) и выдает ему HTTP-запрос. Сервер обрабатывает этот запрос и выдает HTTP-ответ клиенту.
Структура HTTP-запроса
HTTP-запрос состоит из заголовка запроса и тела запроса, разделенных пустой строкой. Тело запроса может отсутствовать.
Заголовок запроса состоит из главной (первой) строки запроса и последующих строк, уточняющих запрос в главной строке. Последующие строки также могут отсутствовать.
Запрос в главной строке состоит из трех частей, разделенных пробелами:
Метод (иначе говоря, команда HTTP):
GET - запрос документа. Наиболее часто употребляемый метод; в HTTP/0.9, говорят, он был единственным.
HEAD - запрос заголовка документа. Отличается от GET тем, что выдается только заголовок запроса с информацией о документе. Сам документ не выдается.
POST - этот метод применяется для передачи данных CGI-скриптам. Сами данные следуют в последующих строках запроса в виде параметров.
PUT - разместить документ на сервере. Насколько я знаю, используется редко. Запрос с этим методом имеет тело, в котором передается сам документ.
Ресурс - это путь к определенному файлу на сервере, который клиент хочет получить (или разместить - для метода PUT). Если ресурс - просто какой-либо файл для считывания, сервер должен по этому запросу выдать его в теле ответа. Если же это путь к какому-либо CGI-скрипту, то сервер запускает скрипт и возвращает результат его выполнения. Кстати, благодаря такой унификации ресурсов для клиента практически безразлично, что он представляет собой на сервере.
Версия протокола -версия протокола HTTP, с которой работает клиентская программа.
Таким образом, простейший HTTP-запрос может выглядеть следующим образом:
Здесь запрашивается корневой файл из корневой директории web-сервера.
Строки после главной строки запроса имеют следующий формат:
Параметр: значениe .
Таким образом задаются параметры запроса. Это является необязательным, все строки после главной строки запроса могут отсутствовать; в этом случае сервер принимает их значение по умолчанию или по результатам предыдущего запроса (при работе в режиме Keep-Alive).
Перечислю некоторые наиболее употребительные параметры HTTP-запроса:
Connection
(соединение)- может принимать значения Keep-Alive и close.
Keep-Alive ("оставить в живых") означает, что после выдачи данного документа
соединение с сервером не разрывается, и можно выдавать еще запросы.
Большинство браузеров работают именно в режиме Keep-Alive, так как он
позволяет за одно соединение с сервером "скачать" html-страницу и рисунки
к ней. Будучи однажды установленным, режим Keep-Alive сохраняется до
первой ошибки или до явного указания в очередном запросе Connection: close.
close ("закрыть") - соединение закрывается после ответа на данный запрос.
User-Agent - значением является "кодовое обозначение" браузера, например:
Mozilla/4.0 (compatible; MSIE 5.0; Windows 95; DigExt)
Accept - список поддерживаемых браузером типов содержимого в порядке их предпочтения данным браузером, например для моего IE5:
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/msword, application/vnd.ms-powerpoint, */*
Это, очевидно, нужно для случая, когда сервер может выдавать один и тот же документ в разных форматах.
Значение этого параметра используется в основном CGI-скриптами для формирования ответа, адаптированного для данного браузера.
Referer - URL, с которого перешли на этот ресурс.
Host - имя хоста, с которого запрашивается ресурс. Полезно, если на сервере имеется несколько виртуальных серверов под одним IP-адресом. В этом случае имя виртуального сервера определяется по этому полю.
Accept-Language - поддерживаемый язык. Имеет значение для сервера, который может выдавать один и тот же документ в разных языковых версиях.
Формат HTTP-ответа
Формат ответа очень похож на формат запроса: он также имеет заголовок и тело, разделенное пустой строкой.
Заголовок также состоит из основной строки и строк параметров, но формат основной строки отличается от таковой в заголовке запроса.
Основная строка запроса состоит из 3-х полей, разделенных пробелами:
Версия протокола - аналогичен соответствующему параметру запроса.
Код ошибки - кодовое обозначение "успешности" выполнения запроса. Код 200 означает "все нормально" (OK).
Словесное описание ошибки - "расшифровка" предыдущего кода. Например для 200 это OK, для 500 - Internal Server Error.
Наиболее употребительные параметры http-ответа:
Connection
- аналогичен соответствующему параметру запроса.
Если сервер не поддерживает Keep-Alive (есть и такие), то значение
Connection в ответе всегда close.
Поэтому, на мой взгляд, правильной тактикой браузера является следующая:
1. выдать в запросе Connection: Keep-Alive;
2. о состоянии соединения судить по полю Connection в ответе.
Content-Type ("тип содержимого") - содержит обозначение типа содержимого ответа.
В зависимости от значения Content-Type браузер воспринимает ответ как HTML-страницу, картинку gif или jpeg, как файл, который надо сохранить на диске, или как что-либо еще и предпринимает соответствующие действия. Значение Content-Type для браузера аналогично значению расширения файла для Windows.
Некоторые типы содержимого:
text/html - текст в формате HTML (веб-страница);
text/plain - простой текст (аналогичен "блокнотовскому");
image/jpeg - картинка в формате JPEG;
image/gif - то же, в формате GIF;
application/octet-stream - поток "октетов" (т.е. просто байт) для записи
на диск.
На самом деле типов содержимого гораздо больше.
Content-Length ("длина содержимого") - длина содержимого ответа в байтах.
Last-Modified ("Модифицирован в последний раз") - дата последнего изменения документа.
Позволяющий получать различные ресурсы, например HTML-документы. Протокол HTTP лежит в основе обмена данными в Интернете. HTTP является протоколом клиент-серверного взаимодействия, что означает инициирование запросов к серверу самим получателем, обычно веб-браузером. Полученный итоговый документ будет реконструирован из различных субдокументов, например, из отдельно полученного текста, описания структуры документа, изображений, видео-файлов, скриптов и многого другого.
Клиенты и серверы взаимодействуют, обмениваясь индивидуальными сообщениями (а не потоком данных). Сообщения, отправленные клиентом, обычно веб-браузером, называются запросами , а сообщения, отправленные сервером, называются ответами .
 Хотя HTTP был разработан еще в начале 1990-х годов, за счет своей расширяемости в дальнейшем он все время совершенствовался. HTTP является протоколом прикладного уровня, который чаще всего использует возможности другого протокола - TCP (или TLS - защищённый TCP) - для пересылки своих сообщений, однако любой другой надежный транспортный протокол теоретически может быть использован для доставки таких сообщений. Благодаря своей расширяемости, он используется не только для получения клиентом гипертекстовых документов либо изображений и видео, но и для передачи контента серверам, например, с помощью HTML-форм. HTTP также может быть использован для получения только частей документа с целью обновления веб-страницы по запросу.
Хотя HTTP был разработан еще в начале 1990-х годов, за счет своей расширяемости в дальнейшем он все время совершенствовался. HTTP является протоколом прикладного уровня, который чаще всего использует возможности другого протокола - TCP (или TLS - защищённый TCP) - для пересылки своих сообщений, однако любой другой надежный транспортный протокол теоретически может быть использован для доставки таких сообщений. Благодаря своей расширяемости, он используется не только для получения клиентом гипертекстовых документов либо изображений и видео, но и для передачи контента серверам, например, с помощью HTML-форм. HTTP также может быть использован для получения только частей документа с целью обновления веб-страницы по запросу.
Компоненты систем, основанных на HTTP
HTTP - это клиент-серверный протокол, то есть запросы отправляются какой-то одной стороной - юзер-агентом (user-agent) (либо прокси вместо него). Чаще всего в качестве юзер-агента выступает веб-браузер, но им может быть кто угодно, например, робот, путешествующий по Сети для пополнения и обновления данных индексации веб-страниц для поисковых систем.
Каждый индивидуальный запрос (англ. request ) отправляется серверу, который обрабатывает его и возвращает ответ (англ. response ). Между этими запросами и ответами существуют многочисленные посредники, называемые прокси , которые выполняют различные операции и работают как шлюзы или кэш , например.
В реальности, между браузером и сервером гораздо больше различных устройств-посредников, которые играют какую-либо роль в обработке запроса: роутеры, модемы и так далее. Благодаря тому, что Сеть построена на основе системы уровней (слоёв) взаимодействия, эти посредники "спрятаны" на сетевом и транспортном уровнях. В этой системе уровней HTTP занимает самый верхний уровень, который называется "прикладным" (или "уровнем приложений"). Знания об уровнях сети, таких как представительский, сеансовый, транспортный, сетевой, канальный и физический, имея важное значение для понимания работы сети и диагностики возможных проблем, не требуются для описания и понимания HTTP.
Клиент: юзер-агент
Юзер-агент - это любой инструмент или устройство, действующие от лица пользователя. Эта роль преимущественно принадлежит веб-браузеру; в некоторых случаях юзер-агентами выступают программы, которые используются инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда является той сущностью, которая инициирует запрос. Сервер никогда этого не делает (хотя за многие годы существования сети были созданы механизмы, которые могут симулировать запросы со стороны сервера).
Чтобы отобразить веб страницу, браузер отправляет начальный запрос для получения HTML-документа этой страницы. После этого браузер анализирует этот документ, и запрашивает дополнительные файлы, необходимые для отбражения содержания веб-страницы (исполняемые скрипты, информацию о макете страницы - CSS таблицы стилей, дополнительные ресурсы в виде изображений и видео-файлов). Далее браузер соединяет все эти ресурсы для отображения их пользователю в виде единого документа - веб-страницы. Скрипты, выполняемые самим браузером, могут получать по сети дополнительные ресурсы на последующих этапах обработки веб-страницы, и браузер соотвествующим образом обновляет представление этой страницы для пользователя.
Веб-страница является гипертекстовый документом. Это означает, что некоторые части отображаемого текста являются ссылками, которые могут быть активированы (обычно нажатием кнопки мыши) с целью получения и соответственно отображения новой веб-страницы. Это позволяет пользователю направлять своего юзер-агента, осуществляя навигацию по Сети. Браузер транслирует эти "направления движения" в HTTP-запросы и в дальнейшем интерпретирует HTTP-ответы в понятном для пользователя виде.
Веб-сервер
На другой стороне коммуникационного канала расположен сервер, который обслуживает (англ. serve ) пользователя, предоставляя ему документы по запросу. С точки зрения конечного пользователя, сервер всегда является некой одной виртуальной машиной, полностью или частично генерирующей документ, хотя фактически он может быть группой серверов, между которыми балансируется нагрузка, то есть перераспределяются запросы различных пользователей, либо сложным программным обеспечением, опрашивающим другие компьютеры (такие как кэширующие серверы, серверы баз данных, серверы приложений электронной коммерции и другие).
Сервер не обязательно расположен на одной машине, и наоборот - несколько серверов могут быть расположены (хоститься) на одной и той же машине. В соответствии с версией HTTP/1.1 и имея Host заголовок, они даже могут делить тот же самый IP-адрес.
Прокси
Между веб-браузером и сервером находятся большое количество сетевых узлов передающих HTTP сообщения. Из за слоистой структуры, большинство из них оперируют также на транспортном сетевом или физическом уровнях, становясь прозрачным на HTTP слое и потенциально снижая производительность. Эти операции на уровне приложений называются прокси . Они могут быть прозрачными, или нет, (изменяющие запросы не пройдут через них), и способны исполнять множество функций:
- caching (кеш может быть публичным или приватными, как кеш браузера)
- фильтрация (как сканирование антивируса, родительский контроль, …)
- выравнивание нагрузки (позволить нескольким серверам обслуживать разные запросы)
- аутотентификация (контролировать доступом к разным ресурсам)
- протоколирование (разрешение на хранение истории операций)
Основные аспекты HTTP
HTTP - прост
Даже с большей сложностью, введенной в HTTP/2 путем инкапсуляции HTTP-сообщений в фреймы, HTTP, как правило, прост и удобен для восприятия человеком. HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более легкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP - расширяемый
Введенные в HTTP/1.0 HTTP-заголовки сделали этот протокол легким для расширения и экспериментирования. Новая функциональность может быть даже введена простым соглашением между клиентом и сервером о семантике нового заголовка.
HTTP не имеет состояния, но имеет сессию
HTTP не имеет состояния: не существует связи между двумя запросами, которые последовательно выполняются по одному соединению. Из этого немедленно следует возможность проблем для пользователя, пытающегося взаимодействовать с определенной страницей последовательно, например, при использовании корзины в электронном магазине. Но хотя ядро HTTP не имеет состояния, куки позволяют использовать сессии с сохранением состояния. Используя расширяемость заголовков, куки добавляются к рабочему потоку, позволяя сессии на каждом HTTP-запросе делиться некоторым контекстом, или состоянием.
HTTP и соединения
Содинение управляется на транспортном уровне, и потому принципиально выходит за границы HTTP. Хотя HTTP не требует, чтобы базовый транспортного протокол был основан на соединениях, требуя только надёжность , или отсутствие потерянных сообщений (т.е. как минимум представление ошибки). Среди двух наиболее распространенных транспортных протоколов Интернета, TCP надёжен, а UDP -- нет. HTTP впоследствии полагается на стандарт TCP, являющийся основанным на соединениях, несмотря на то, что соединение не всегда требуется.
HTTP/1.0 открывал TCP-соединение для каждого обмена запросом/ответом, имея два важных недостатка: открытие соединения требует нескольких обменов сообщениями, и потому медленно, хотя становится более эффективным при отправке нескольких сообщений, или при регулярной отправке сообщений: теплые соединения более эффективны, чем холодные .
Для смягчения этих недостатков, HTTP/1.1 предоставил конвеерную обработку (которую оказалось трудно реализовать) и устойчивые соединения: лежащее в основе TCP соединение можно частично контролировать через заголовок Connection . HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение теплым и более эффективным.
Проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP. Например, Google эксперементирует с QUIC , которая основана на UDP, для предоставления более надёжного и эффективного транспортного протокола.
Чем можно управлять через HTTP
Естественная расширяемость HTTP со временем позволила большее управление и функциональность Сети. Кэш и методы аутентификации были ранними функциями в истории HTTP. Способность ослабить первоначальные ограничения, напротив, была добавлена в 2010-е.
Ниже перечислены общие функции, управляемые с HTTP.
-
Сервер может инструктировать прокси и клиенты: что и как долго кэшировать. Клиент может инструктировать прокси промежуточных кэшей игнорировать хранимые документы. - Ослабление ограничений источника
Для предотвращения шпионских и других, нарушающих приватность, вторжений, веб-браузер обчеспечивает строгое разделеление между веб-сайтами. Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности). - Аутентификация
Некоторые страницы доступны только специальным пользователям. Базовая аутентификация может предоставляться через HTTP, либо через использование заголовка WWW-Authenticate и подобных ему, либо с помощью настройки спецсессии, используя куки. - Прокси и тунелирование
Серверы и/или клиенты часто располагаются в интранете, и скрывают свои истинные IP-адреса от других. HTTP запросы идут через прокси для пересечения этого сетевого барьера. Не все прокси -- HTTP прокси. SOCKS-протокол, например, оперирует на более низком уровне. Другие, как, например, ftp, могут быть обработаны этими прокси. - Сессии
Использование HTTP кук позволяет связать запрос с состоянием на сервере. Это создает сессию, хотя ядро HTTP -- протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.
HTTP поток
Когда клиент хочет взаимодействовать с сервером, являясь конечным сервером или промежуточным прокси, он выполняет следующие шаги:
- Открытие TCP соединения: TCP-соедиенение будет использоваться для отправки запроса или запросов, и получения ответа. Клиент может открыть новое соединение, переиспользовать существующее, или открыть несколько TCP-соединений к серверу.
- Отправка HTTP-сообщения: HTTP-собщения (до HTTP/2) -- человеко-читаемо. Начиная с HTTP/2, простые сообщения инкапсилуруются во фреймы, делая невозможным их чтения напрямую, но принципиально остаются такими же. GET / HTTP/1.1 Host: сайт Accept-Language: fr
- Читает ответ от сервера: HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html
- Закрывает или переиспользует соединение для дальнейщих запросов.
Если активирован HTTP-конвеер, несколько запросов могут быть отправлены без ожидания получения первого ответа целиком. HTTP-конвеер тяжело внедряется в существующие сети, где старые куски ПО сосуществуют с современными версиями. HTTP-конвеер был заменен в HTTP/2 на более надежные мультиплексивные запросы во фрейме.
HTTP сообщения
HTTP/1.1 и более ранние HTTP сообщения человеко-читаемы. В версии HTTP/2 эти сообщения встроены в новую бинарную структуру, фрейм, позволяющий оптимизации, такие как компрессия заголовков и мультиплексирование. Даже если часть оригинального HTTP сообщения отправлена в этой версии HTTP, семантика каждого сообщения не изменяется и клиент воссоздаёт (виртуально) оригинальный HTTP-запрос. Это также полезно для понимания HTTP/2 сообщений в формате HTTP/1.1.
Протокол HTTP или HyperText Transfer Protocol это главный прокол (всемирной паутины). Основная задача протокола, обеспечить передачу гипертекста в сети. В протоколе точно описывается формат сообщений, для обмена клиентов и серверов.
Описан протокол HTTP в RFC 2616(HTTP1.1).
Основа протокола обеспечить взаимодействие клиента и сервера по средством одного ASCII-запроса, и следующего на него ответа в стандарте RFC 822 MIME.
На практике протокол HTTP работает на основе порт 80, но можно настроить и по-другому. И хоть TCP/IP не является обязательным, он остается предпочтительным, так как берет на себя разбиение и сборку сообщений на себя и не «напрягает» ни браузер, ни сервер.
Следует отметить, что протокол HTTP может использоваться не только в веб-технологиях, но и других ООП приложениях (объективно-ориентированных).
URL
Основой веб-общения клиент-сервер является запрос. Запрос отправляется при помощи URL– единого указателя ресурсов Интернет. Напомню, что такое URL адрес.
Понятная и простая структура URL состоит из следующих элементов:
- Протокол;
- Хост;
- Порт;
- Каталок ресурса;
- Метки (Запрос).
Примечание: Протокол http это протокол для простых, не защищенных соединений. Защищенные соединения работают по протоколу https. Он более безопасен для обмена данными.
Методы HTTP запросов
Один из параметров URL, определяет название хоста, с которым мы хотим общаться. Но этого мало. Нужно определить действие, которое нужно совершить. Сделать это можно при помощи метода определенного протоколом HTTP.
Методы HTTP
- Метод/Описание
- HEAD/Прочитать заголовок веб-страницы
- GET/Прочитать веб-страницу
- POST/Добавить к веб-странице
- PUT/Сохранить веб-страницу
- TRACE/Отослать назад запрос
- DELETE/Удалить веб-страницу
- OPTIONS/Отобразить параметры
- CONNECT/Зарезервировано для будущего использования
Разберем методы HTTP подробнее
Метод GET.
запрашивает страницу (файл, объект), закодированную по стандарту MIME. Это самый употребляемый метод. Структура метода:
GET имя_файла HTTP/1.1
Метод HEAD. Этот метод запрашивает заголовок сообщения. При этом страница не загружается. Этот метод позволяет узнать время последнего обновления страницы, что нужно для управления КЭШем страниц. Этот метод позволяет проверить работоспособность запрашиваемого URL.
Метод PUT. Этот метод может поместить страницу на сервер. Тело запроса PUT включает размещаемую страницу, которая закодирована по MIME. Это метод требует идентификации клиента.
Метод POST. Этот метод добавляет содержимое к уже имеющейся странице. Используется, как пример, для добавления записи на форум.
Метод DELETE. Этот метод уничтожает страницу. Метод удаления требует подтверждения прав пользователя на удаление.
Метод TRACE. Этот метод отладки. Он указывает серверу отослать запрос назад и позволяет узнать, искажается или нет, запрос клиента, вернувшись от сервера.
Метод CONNECT – метод резерва, не используется.
Метод OPTIONS позволяет запросить свойства сервера и свойства любого файла.
В общении клиента и сервера «запрос-ответ», сервер обязательно генерирует ответ. Это может быть веб-страница или строку состояния с кодом состояния. Код состояния вам хорошо известен. Один из кодов известный код 404 –Страница не найдена.
Группы кодов состояния
1хх: Готовность сервера, Код 100 – сервер готов обрабатывать запросы клиента;
2хх: Успех.
- Код 200 – запрос обработан успешно;
- Код 204 – Содержимого нет.
3хх: Перенаправление.
- Код 301 – Запрашиваемая страница перенесена;
- Код 304 – Страница в КЭШе еще актуальна.
4хх: Ошибка клиента.